
AE系列

技术思想及原理分析
AE模型(Auto Encoder)就是自编码模型,自编码的工作是让输入数据自己给自己编码,简单来说就是让输出等于输入!那么为什么要这么做呢?有必要让输出等于输入吗?如果输入是一张图片,那么直接复制一张图片作为输出不就行了吗?为什么要费尽心思让输出数据和输入数据一样呢?
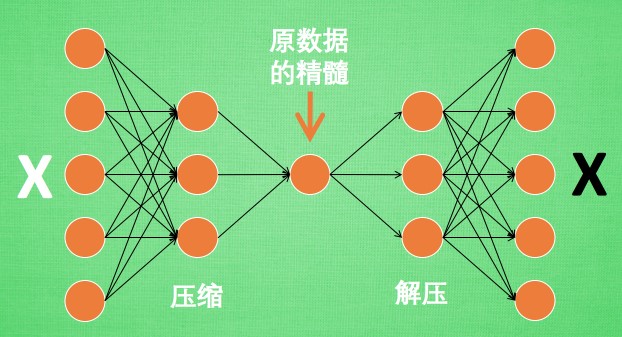
通过左图,我们发现自编码是先把输入数据进行压缩成特征精髓,然后再对压缩过后的特征精髓进行解压缩还原,这是不是和我们的文件压缩和解压缩非常相似,其实二者原理是一样的,只不过文件压缩是无损压缩,而自编码模型对输入数据进行的是有损压缩,可以理解为自编码模型在压缩过程中,丢掉了部分不重要的特征,然后留下的是主要特征。在解压缩的时候,通过网络的学习,再去还原丢掉的那部分不重要的特征信息。由于神经网络是一个函数模拟器,网络是会学到一些特征,但是和丢掉的那部分特征又不完全一样,这就造成了网络输出的数据和输入数据很相似,但又不是完全一样的数据。

应用场景及商业价值
上面说了很多自编码的原理和过程,发现自编码虽然是尽量让输出等于输入,但是由于神经网络的极限逼近问题,其实它所得到的输出数据是和原输入非常接近但又不相同的数据,这正是自编码的目的,只有这样才能造成数据的多样性,通过自编码的这种多样性可以用来生成样本,扩大有效样本的数据量。自编码通过不同的变种可以做不同的事情,比如通过降噪自编码对图像进行去噪处理,可以得到一张更加清晰的图像。有的时候也可以通过自编码做一些比较有趣的小案例。左图是对手写数字增加噪声后,使用降噪自编码得到的输出结果。可以看到降噪后输出的结果和原数据之间,除了在细节上展现出了不同之处,其数字基本是一致的。
VAE
技术思想及原理分析
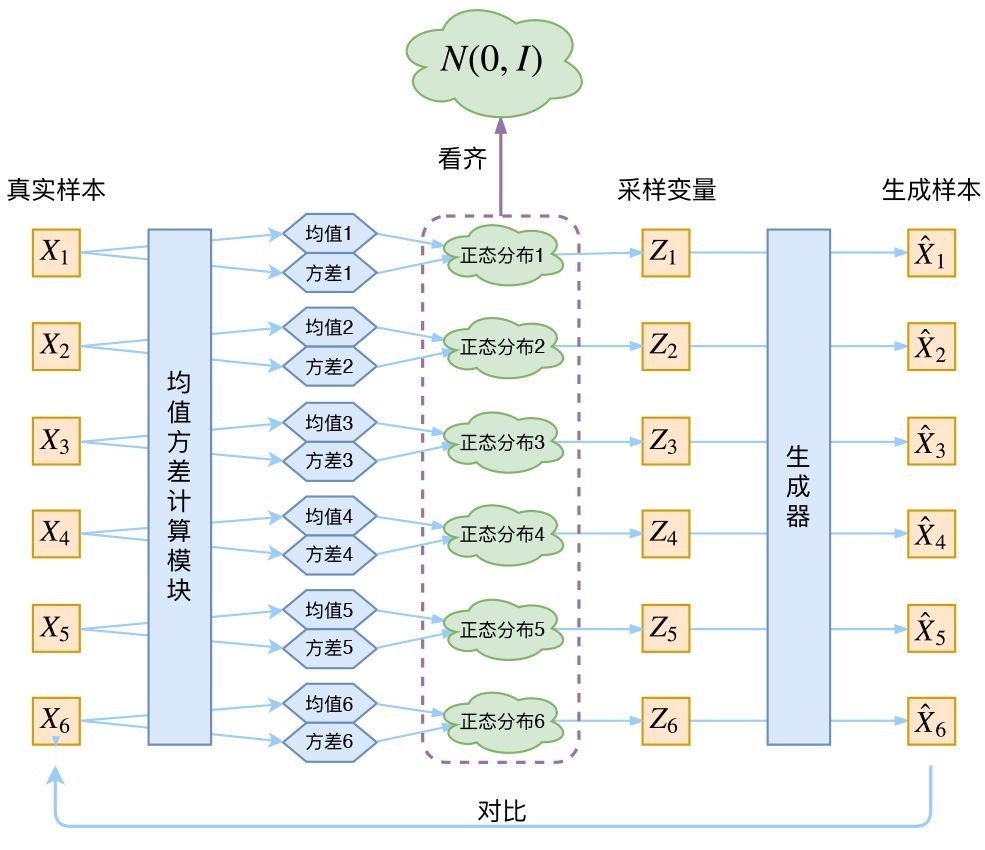
变分自编码VAE(Variational auto-encoder)是AE模型的一种特殊变种模型,其主要思想是在AE的基础上对输入的原数据的分布进行轻微扰动,使其产生多样性。具体做法就是让模型学习原数据的统计值μ和σ为标准正态分布的μ和σ,而不是学习数据本身,然后再从标准正态分布进行采样获得具体的数据值,在将统计量和具体数据值结合,形成新的数据通过一个生成器学习原数据的分布。

应用场景及商业价值
VAE的应用场景主要体现在生成类方面,比如生成新的图像数据等,和AE模型相比,VAE由于加入了新的标准正态分布数据,使得生成数据更具多样性。下图展示了VAE对手写数字生成的一个效果。从图上可以看出,通过对输入数据的分布进行一定的扰动,得到的生成数据会发生一定变化,有的数据甚至改变了值。
GAN系列

技术思想及原理分析
生成式对抗神经网络GAN(Generative Adversarial Networks )是另一种非常有意思的生成类模型,和VAE不一样的是,GAN是通过一个判别器和生成器之间的模仿游戏来完成数据的生成的,其损失函数就是一个交叉熵,没有VAE的损失设计那么复杂,原理也更简单。而VAE是通过调整原数据的分布来生成新的数据的。相比较而言,GAN是直接学习原始数据的每部分特征分布,然后再组合每部分的分布数据合成的一张新图。由于直接学习数据本身的分布,训练好的GAN输出的图像更加清晰,细节部分表现更好,而VAE是对分布的方差进行一定扰动,也就是改变了细节,VAE更加关注全局,生成的图像细节没有GAN那么好。

应用场景及商业价值
GAN的应用比VAE更加广泛,GAN应用到一些场景上,比如图像风格迁移,超分辨率,图像补全,去噪,避免了损失函数设计的困难,只要有一个的基准,直接加上判别器,剩下的就交给对抗训练了。由于GAN的变种非常多,比如CGAN、DCGAN、WGAN等,以及近两年的高清图像生成模型Style GAN等,所以基本上能看到的一些生成类模型都以GAN为主。下面是GAN对手写数字和卡通人脸的生成效果展示,可以看出GAN的生成效果要明显好于VAE的生成效果。