
语音唤醒

技术思想及原理分析
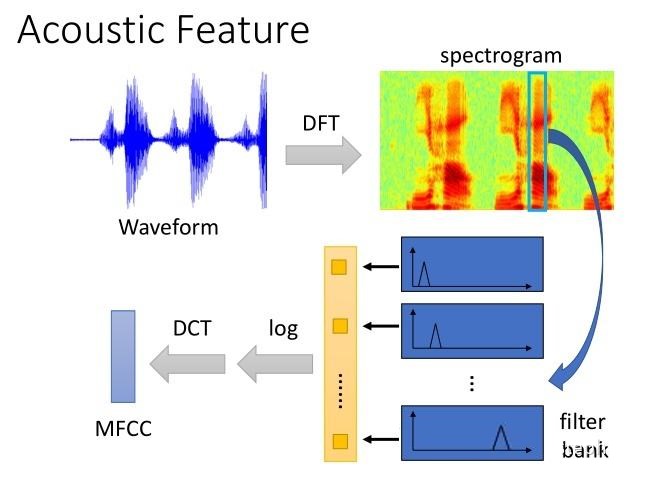
语音唤醒的原理是让模型学习特定唤醒词的语音信号特征,当输入设备捕捉到一定阈值范围内的语音信号时,当前设备将会被唤醒,否则平时设备都处于待机状态。比如小米音箱这款产品,我们在使用的时候,一般都会喊一声“小爱同学”,然后再让它执行我们的命令,比如换一首歌,或者减小音量。这个“小爱同学”所发出的语音信号就是模型要学习的标签,当模型学到一定的标签数量时,下次再听到这个标签的声音时,就会做出反应,设备也就被唤醒了。语音唤醒的方法有很多,有基于传统机器学习的方法,也有基于深度学习的方法,这里只分享一些目前比较流行的深度学习方法,比如有基于CNN的Keyword Spotting模型、基于CRNN的Keyword Spotting模型、基于SEQ2SEQ的Keyword Spotting模型等。无论是那种方法,一般会将先语音波形图转成频谱图,频谱图通过Mel滤波器组得到Mel频谱,然后在Mel频谱上进行倒谱分析,获得Mel频率倒谱系数MFCC,MFCC就是语音的特征;这时候,语音就可以通过一系列的倒谱向量来描述了,每个向量就是每帧的MFCC特征向量。这样就可通过这些倒谱向量对语音分类器进行训练和识别了。
应用场景及商业价值
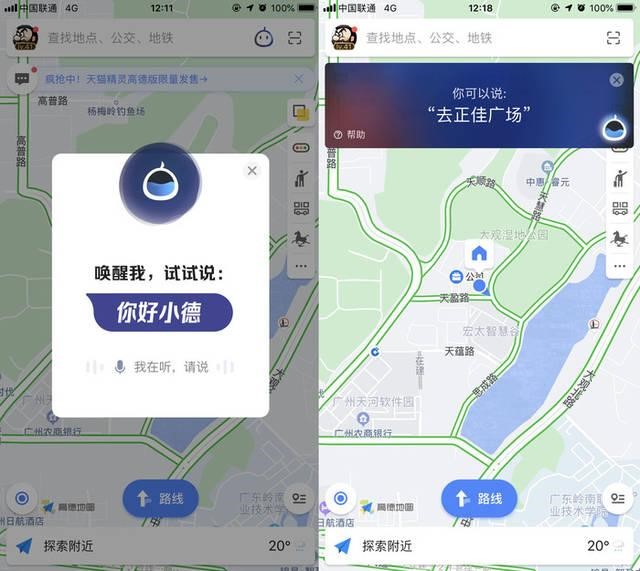
目前市场上几乎所有的智能语音产品都有语音唤醒装置,在执行任何一句命令之前,都要加上一个关键词来唤醒设备,其主要功能在于更好的执行命令,以及节能和延长设备使用寿命,如果一台语音设备没有唤醒装置,就意为着它无时无刻都是开机状态的,想要对他发号施令,就要求设备的智能程度非常高才行,不然设备很难判断你是在对它发号施令,还是在和你的朋友聊天;这种情况会造成更多的能源消耗,对设备使用寿命也将损耗不少。