关于AIGC系列的文章内容,我们在上一期介绍了基础模型Transformer,本期将会继续介绍基于Transformer模型改进的BERT(双向编码器表示Transformer)模型。如果想要查之前的介绍内容,可以关注本号,翻看之前的文章。
六、BERT(双向编码器表示Transformer)
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的预训练模型,由Google于2018年提出。其论文 "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" 由Jacob Devlin等人于2018年发布。
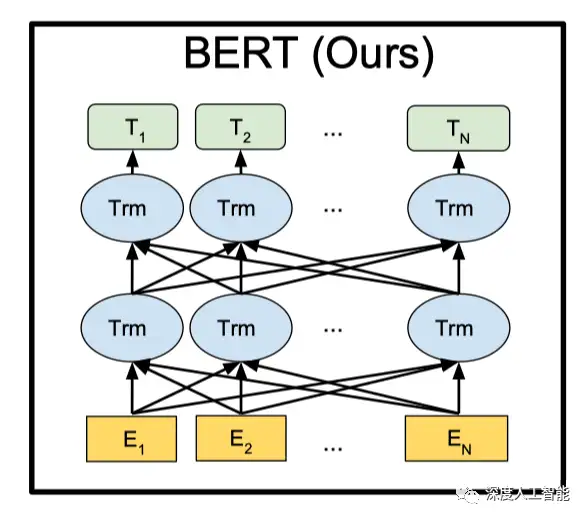
BERT的主要原理是通过使用无标签的大规模文本数据进行预训练,学习到通用的语言表示,并在下游任务上进行微调,属于pretraining+fine tuning的学习模式。BERT的关键思想是双向编码器和Transformer自注意力机制。关于自注意力机制在上面的Transformer模型中已经有了详细的介绍,接下来简单介绍一下BERT模型中的双向编码器和它的结构及运行过程。
在BERT模型中,双向编码器是指模型能够同时考虑上下文的双向信息,从而更好地捕捉语言的语义和关联。传统的语言模型(如循环神经网络)通常只能单向地处理语言序列,而BERT通过引入Transformer的自注意力机制实现了双向编码。
BERT的结构层次是由输入嵌入层、多个编码器层、预训练任务层和微调层组成。这个层次结构使BERT模型能够学习到通用的语言表示,并在下游任务上展现出强大的性能。通过预训练和微调的方式,BERT模型在自然语言处理任务中取得了显著的成功。
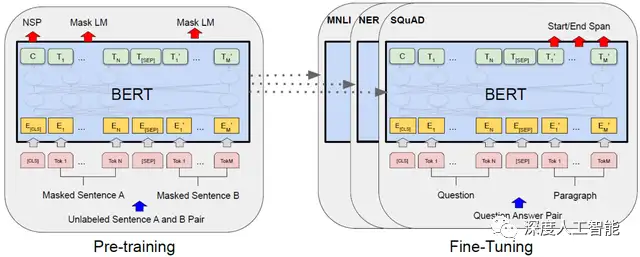
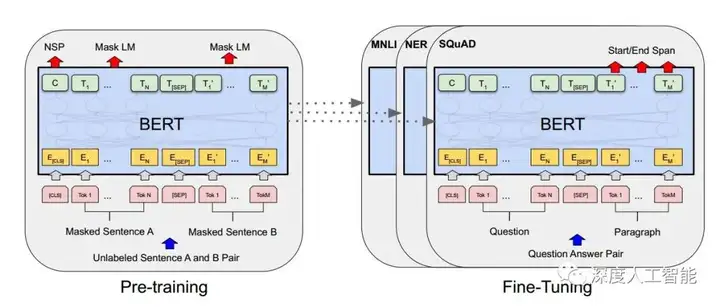
BERT(Bidirectional Encoder Representations from Transformers)模型的训练过程包括两个主要阶段:预训练和微调。预训练阶段旨在通过大规模的无标签语料库学习通用的语言表示,而微调阶段则在特定任务的有标签数据上微调预训练的表示。
1. 预训练阶段:
在预训练阶段,BERT模型通过两个不同的预训练任务进行训练:
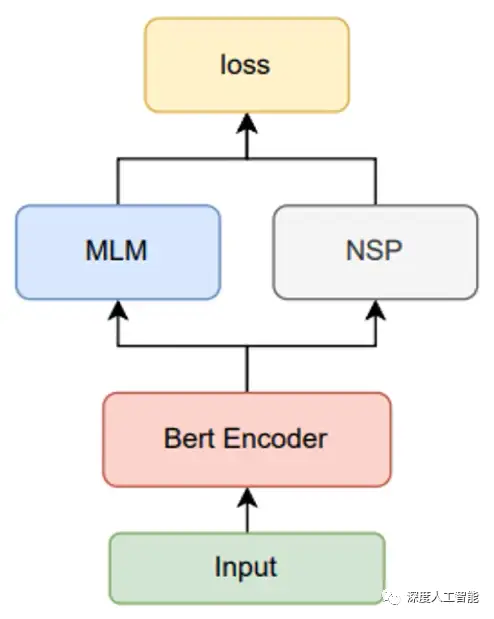
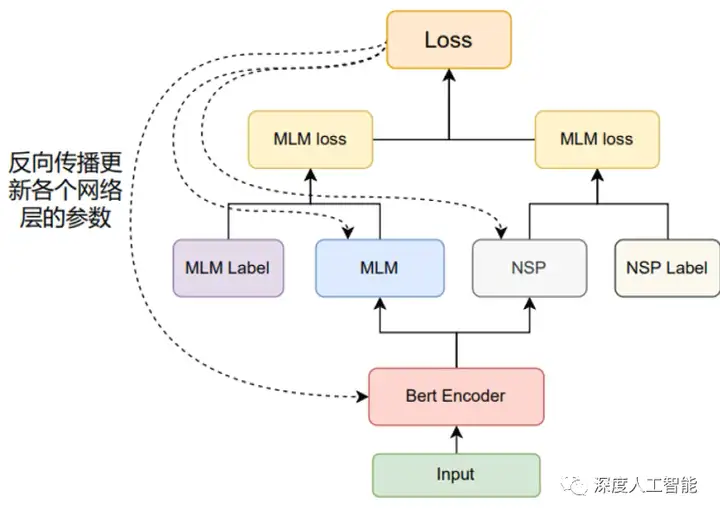
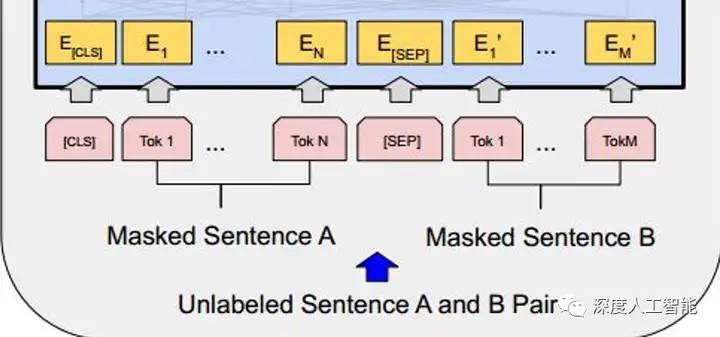
a. Masked Language Model(MLM):对于输入的句子,随机遮盖其中一些单词,然后模型需要根据上下文预测被遮盖单词的内容。这个任务鼓励模型在理解上下文的情况下学习单词的语义和关系。
b. Next Sentence Prediction(NSP):随机选择一对句子,模型需要判断第二个句子是否是第一个句子的下一句。这个任务帮助模型理解句子之间的关系,如上下文连接和逻辑关系。
通过这两个任务,BERT模型学会了丰富的语言表示,从而能够捕捉单词和句子的语义特征。
2. 微调阶段:
在预训练完成后,BERT模型的表示可以被用于各种下游任务,如文本分类、命名实体识别、问答等。微调阶段的步骤如下:
a. 任务特定结构和损失:针对特定的任务,将与任务相关的结构添加到BERT模型的顶部,并且调整相应的输出层。例如,对于文本分类任务,可以添加一个分类层。此外,适用于任务的损失函数也会被定义。
b. 微调:使用有标签的任务数据,对预训练的BERT模型进行有监督的微调。在这个阶段,模型将根据任务的标签进行反向传播和参数更新,以逐步调整模型的表示,使其适应特定任务。
通过预训练和微调的两个阶段,BERT模型能够学习通用的语言表示,并且能够在各种下游任务中表现出色。这种两阶段的训练策略使得BERT在自然语言处理领域取得了显著的突破。
BERT的运行过程如下:
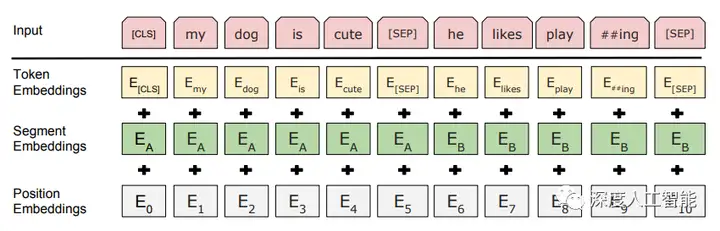
1. 输入编码:BERT的输入是由单词或字符级别的文本序列组成。这些输入序列首先会经过一层词嵌入(word embedding)或字符嵌入(character embedding),将每个单词或字符映射到连续的向量表示。
2. 位置编码:为了捕捉序列中的位置信息,和Transformer一样,BERT也引入了位置编码。上文介绍过,位置编码是一种向量表示,它根据单词或字符在序列中的位置来表示位置信息。由于全连接的模型不像循环神经网络那般具有“记忆”,我们需要位置编码与输入的词嵌入或字符嵌入相加,得到输入的位置嵌入。
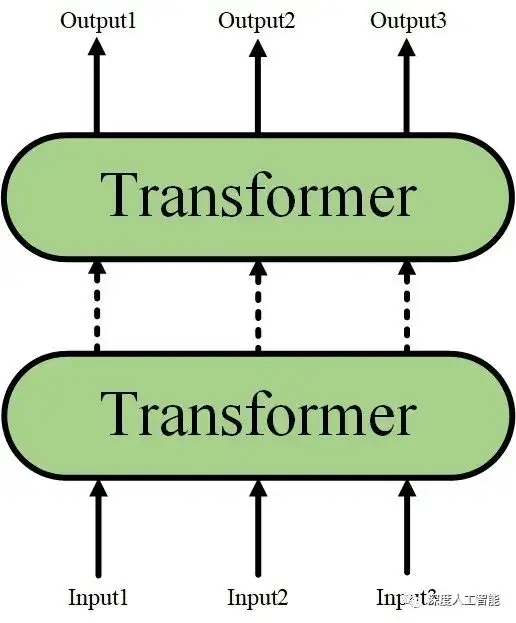
3. 编码器堆叠:BERT模型由多个编码器层(Transformer的一种形式)堆叠而成。每个编码器层由多头自注意力机制和前馈神经网络组成。堆叠编码器的目的是为了增加模型的表示能力和深度。通过堆叠多个编码器层,BERT能够更好地学习输入序列的复杂语义和关联。
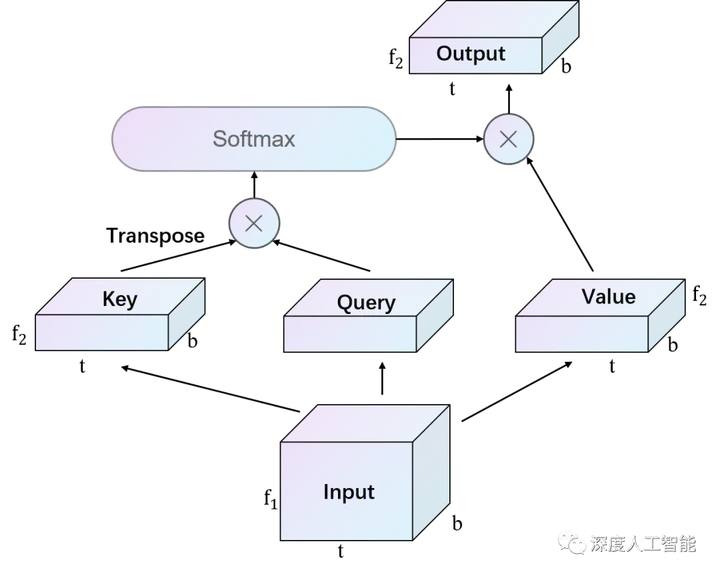
a. 多头自注意力机制:与Transformer一样,BERT模型在每个编码器层中,输入经过多个注意力头的自注意力机制。自注意力机制允许模型在序列中的不同位置进行交互,将每个位置的信息与其他位置相关联。
b. 前馈神经网络(即全连接网络):自注意力机制后面是一个前馈神经网络,它由两个全连接层组成。前馈神经网络通过对自注意力机制的输出进行非线性变换,从而提供更丰富的表示能力。
堆叠编码器使BERT模型具有模块化的结构。每个编码器层可以单独进行训练和微调,也可以根据任务需求进行堆叠和调整。这种灵活性使得BERT模型可以应用于不同的下游任务,并且可以根据任务特定的数据和特征进行微调和优化。
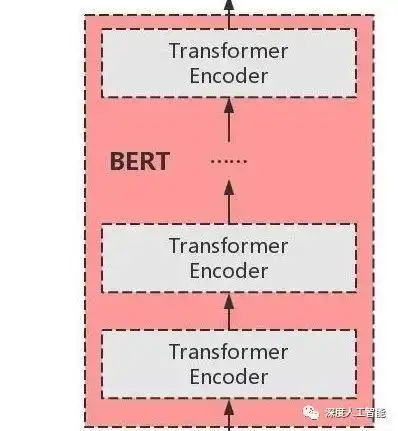
通过堆叠编码器层,BERT模型能够获得更强大的表示能力和深度建模能力,从而提高了模型的性能和泛化能力。这也是BERT在自然语言处理任务中取得显著成果的关键因素之一。
4. 堆叠的编码器输出:在经过多个编码器层之后,BERT模型的输出是堆叠的编码器层的最终输出。这些输出包含了整个输入序列的双向编码信息。

BERT模型通过预训练和微调的方式使用双向编码器进行训练和微调模型。在预训练阶段,BERT使用大规模无标签数据进行训练,通过自监督学习来学习通用的语言表示。在微调阶段,BERT模型可以在下游任务上进行微调,如文本分类、命名实体识别等,以适应特定任务的需求。
通过双向编码器,BERT模型能够在一个模型中同时考虑上下文的双向信息,从而提高了对语言的理解和建模能力。这使得BERT在各种自然语言处理任务中取得了很不错的性能提升。
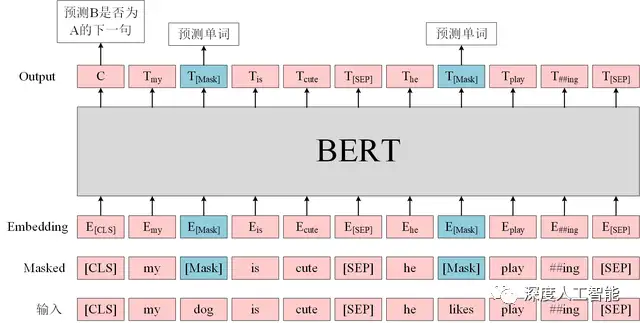
在预测上下文方面,BERT与一般在传统的语言模型也不同。在传统语言模型中,通常只使用左侧或右侧的上下文来预测下一个单词。而BERT引入了"Masked Language Model"(MLM)任务,即在预训练阶段随机遮盖一些输入的词,并尝试预测这些被遮盖的词。这使得模型能够双向地理解上下文,提高了模型对语言的理解能力。
我们知道BERT模型的架构是基于Transformer的,而Transformer由多个编码器层组成,每个编码器层包含多头自注意力机制和前馈神经网络。在BERT中,通过堆叠多个编码器层,模型可以学习到更深层次的语言表示。
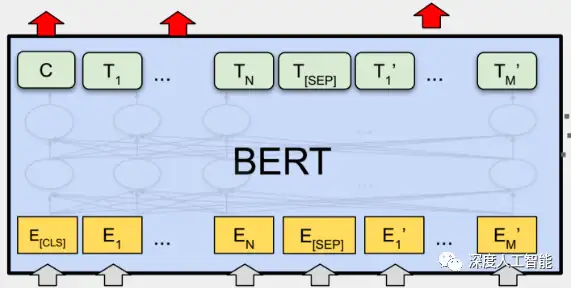
在预训练阶段,BERT使用大规模的无标签文本数据进行训练,其中包括BookCorpus和Wikipedia等数据集。通过预测被遮盖的词,以及预测句子间关系(即判断两个句子是否连续出现),BERT学习到了丰富的语言表示。
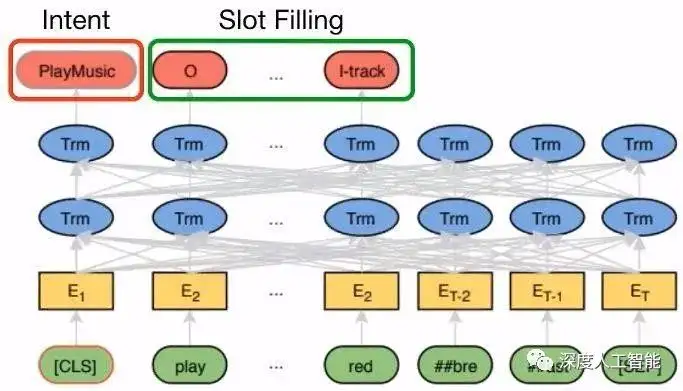
在微调阶段,BERT模型可以用于各种下游自然语言处理任务,如文本分类、命名实体识别、问答系统等。通过在特定任务上进行微调,BERT可以适应不同的任务需求,提高模型性能。
BERT和Transformer在自然语言处理中都扮演着重要的角色,BERT是基于Transformer的一种变种模型。Transformer是一种强大的神经网络架构,用于处理序列数据,比如语言。它通过自注意力机制,让模型能够同时关注输入序列中的所有位置,并捕捉到全局的语义信息。你可以把它看作一个很聪明的模型,能够理解输入序列中不同位置之间的关系。
而BERT则是在Transformer的基础上进行了改进。它通过在大规模无标签的文本数据上进行预训练,学习到通用的语言表示。BERT还引入了一些有趣的预训练任务,比如遮盖语言模型和下一句预测,让模型更好地理解上下文和推理能力。
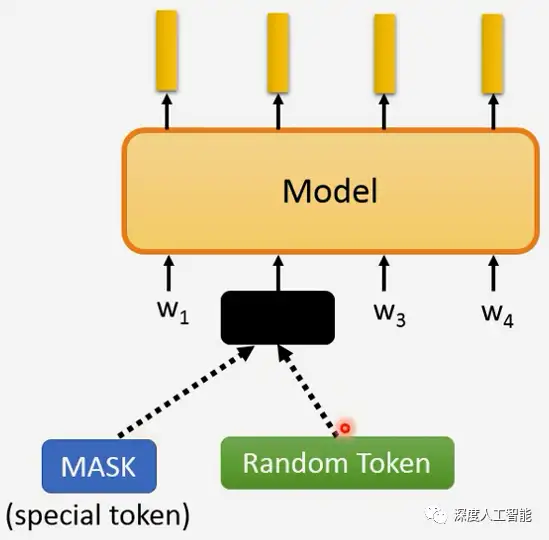
所以说,Transformer是一种网络架构,而BERT是基于Transformer的一种具体实现。它们的目标都是让模型能够更好地理解语言,但BERT在模型结构和预训练任务上有一些独特的改进,使其在自然语言处理任务中表现出色。
下面时对BERT模型的基本架构代码实现,由于BERT模型的复杂性和代码长度,这里仅实现基本架构代码。其中包括BERT模型的主要组件,以及每个组件的注释说明。这里只是一个基本的框架,具体需要根据实际需求进行修改和完善。
import torch
import torch.nn as nn
from transformers import BertModel, BertConfig
class BertForCustomTask(nn.Module):
def __init__(self, config):
super(BertForCustomTask, self).__init__()
# 加载预训练的BERT模型
self.bert = BertModel.from_pretrained('bert-base-uncased', config=config)
# 添加自定义的任务特定层
self.task_specific_layer = nn.Linear(config.hidden_size, num_labels)
def forward(self, input_ids, attention_mask):
# BERT的前向传播
outputs = self.bert(input_ids, attention_mask=attention_mask)
# 获取BERT模型的最后一层隐藏状态
last_hidden_state = outputs.last_hidden_state
# 进行任务特定的操作,如分类、命名实体识别等
logits = self.task_specific_layer(last_hidden_state[:, 0, :]) # 取CLS特征作为整个序列的表示
return logits
# 设置Bert配置
config = BertConfig.from_pretrained('bert-base-uncased')
num_labels = 2 # 自定义任务的标签数
# 创建Bert模型
model = BertForCustomTask(config)
# 创建输入数据
input_ids = torch.tensor([[1, 2, 3, 0, 0], [4, 5, 6, 7, 8]]) # 输入序列的token id
attention_mask = torch.tensor([[1, 1, 1, 0, 0], [1, 1, 1, 1, 1]]) # 输入序列的attention mask
# 进行前向传播
logits = model(input_ids, attention_mask)
print(logits.size()) # 输出logits的形状上面的这段代码使用了Hugging Face的transformers库来加载预训练的BERT模型。使用时需要确保已安装此库,可以使用`pip install transformers`进行安装。
此代码框架创建了一个自定义任务的BERT模型。它加载了预训练的BERT模型,并在其之上添加了一个任务特定的线性层。在前向传播中,输入数据通过BERT模型并进行任务特定的操作。
Transformer模型和BERT模型都在自然语言处理领域具有广泛的应用。下面是对Transformer模型和BERT模型的区别介绍,分别从它们各自的特点与适合的应用领域等方面进行了简单的对比介绍。
BERT模型相对于标准Transformer模型的一些特点:
1. 网络模型结构:Transformer是一种通用的神经网络架构,适用于处理序列数据,不仅限于自然语言处理。BERT是基于Transformer的一种具体实现,专注于自然语言处理任务。
2. 双向注意力机制:在Transformer中,自注意力机制(Self-Attention)用于计算每个单词与其它单词之间的关系。BERT将这个机制扩展为双向,也就是说,每个单词都可以同时看到它前面和后面的单词。这种双向性使BERT能够更好地理解单词在上下文中的含义。
3. 预训练目标:BERT采用了两个预训练任务:Masked Language Model(MLM)和Next Sentence Prediction(NSP)。在MLM任务中,输入句子的一部分被随机遮盖,模型需要预测被遮盖的单词是什么。在NSP任务中,两个句子作为输入,模型需要预测第二个句子是否是第一个句子的下一句。这些任务的预训练使BERT学会了丰富的语言表示。
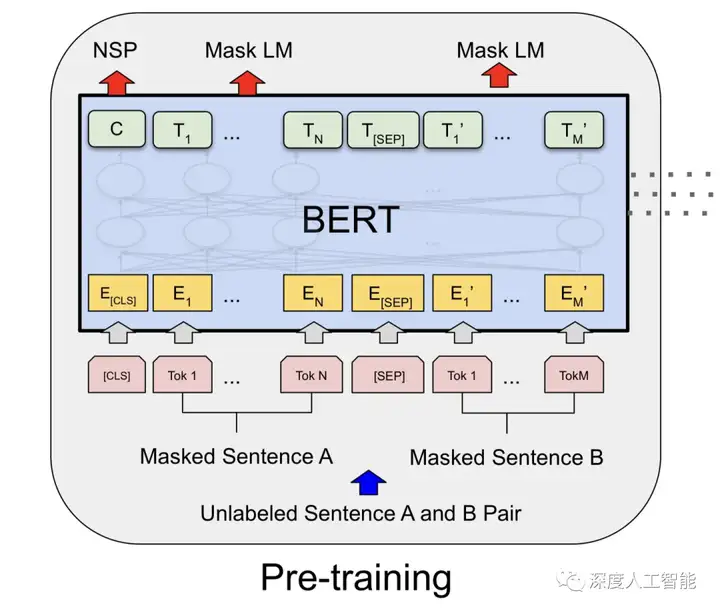
4. 无监督预训练和有监督微调:BERT的训练过程分为两个阶段。首先,在大规模无标签语料库上进行无监督预训练,学习通用的语言表示。然后,在特定任务的有标签数据上进行微调,使模型适应特定任务。
5. Transformer Blocks堆叠:BERT模型由多个Transformer Blocks(通常为12或24个)堆叠而成。每个Transformer Block包含多头自注意力和前馈神经网络。这些堆叠的Blocks使BERT能够捕捉不同层次的语言特征。
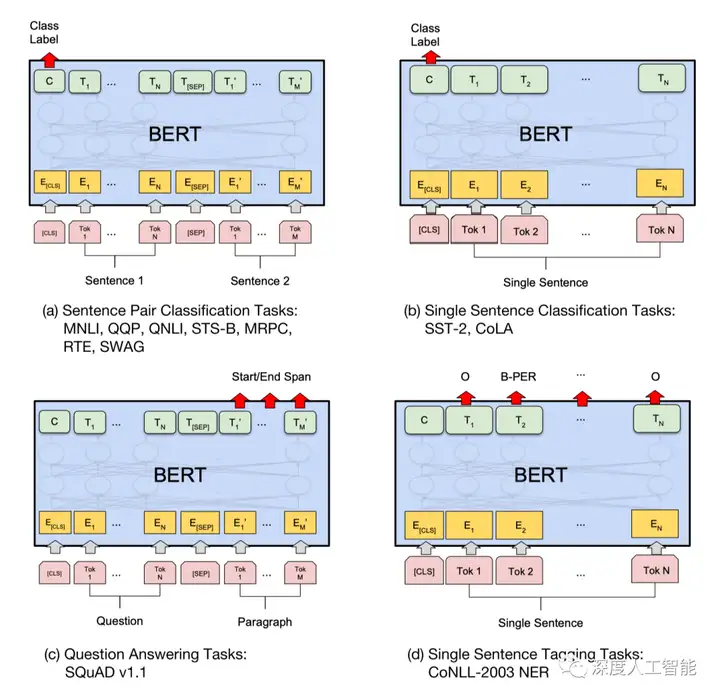
6. Fine-Tuning:BERT的预训练表示可以被用于各种下游任务,如文本分类、命名实体识别、问答等。在微调阶段,可以将特定任务的标签信息和BERT的预训练表示结合起来,进行有监督的训练。BERT在自然语言处理任务中取得了显著的性能提升,并在多项任务上超越了之前的模型。Transformer作为一个通用框架,具有广泛的适用性和出色的性能,但其性能可能低于经过预训练和微调的BERT模型。
Transformer模型的应用领域:
1. 机器翻译:Transformer模型在机器翻译任务中取得了巨大的成功,其能够将一种语言的序列翻译成另一种语言的序列。
2. 文本摘要:Transformer模型在生成文本摘要方面也有很好的效果,能够从长篇文章中自动提取关键信息并生成简洁的摘要。
3. 语义理解:Transformer模型在自然语言理解任务中具有出色的表现,如文本分类、命名实体识别、情感分析等。
4. 对话系统:Transformer模型可用于构建强大的对话系统,如聊天机器人、客服系统等。
BERT模型的应用领域:
1. 文本分类:BERT模型可用于文本分类任务,如情感分析、垃圾邮件检测、新闻分类等,它能够对文本进行精确的分类。
2. 命名实体识别:BERT模型能够识别文本中的命名实体,如人名、地名、组织名等。
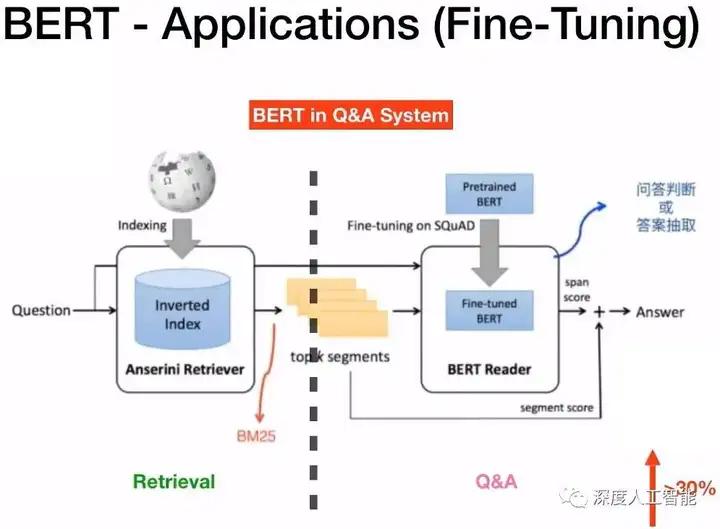
3. 问答系统:BERT模型在问答系统中表现出色,能够理解问题并从文本中找到正确的答案。
4. 自然语言推理:BERT模型可用于判断两个句子之间的逻辑关系,如蕴含、矛盾、中立等。
5. 信息检索:BERT模型可用于改进搜索引擎的性能,提高搜索结果的准确性和相关性。
最后总结一下,Transformer是一种通用的序列建模框架,而BERT是基于Transformer的专门用于自然语言处理的模型,BERT在Transformer架构的基础上引入了双向上下文信息和预训练目标,使其能够更好地理解语境,从而在各种自然语言处理任务中表现出色。两者在应用领域和训练方法上有一些差异,BERT在自然语言处理任务中的效果更为突出,但Transformer作为一个通用框架具有更广泛的适用性。
顺便介绍一下,BERT和之前文章中介绍过的ELMo模型一样,都是美国儿童节目《芝麻街》当中的人物,可能是BERT的作者为了致敬ELMo的作者,也有可能是巧合。两位角色在节目中的个性鲜明,深受大家的喜爱,不同于声音清亮,笑声有感染力,整天大叫着“ELMO wants to play!”的ELMO,BERT长期忍受着另外一个角色ERNIE的取笑,他对人特别认真,任何事都可以令他沉迷,他最喜欢收集瓶盖和回形针,还喜欢管弦乐和他的宠物鸽子。虽然ERNIE一直取笑和捉弄他,但是他总是能原谅ERNIE,永远做他的好朋友。

本期对BERT模型的简单介绍就到此结束了,下一期我们将介绍基于Transformer基础模型的改进模型GPT(Generative Pre-trained Transformer)。













