文章接 —— AIGC之文本内容生成概述(下)——GPT(1)
ØGPT-3
2020年5月28日,OpenAI发布新模型GPT-3。GPT-3被设计用来回答各种自然语言问题,并提供相关的知识和信息。同年6月11日,OpenAI将GPT-3以API的方式向学术机构、商业公司和个人开发者提供了一些需要申请的体验资格,并在同年9月将GPT-3授权给微软公司。
对于所有任务,通过纯文本来指定任务和少量样本,GPT-3可以在无需任何梯度更新或微调的情况下被使用。对于GPT-3生成的新闻文章,评估员甚至无法区分其与人类撰写的新闻文章。
GPT-3在GPT-2的基础上进行了改进和扩展。它使用了更强大的Transformer模型架构,同时增加了更多的参数和更大的语料库,具有超过1750亿个参数,相比GPT-2,GPT-3在语言理解、生成和推理等方面表现更加出色,能够进行更加复杂的自然语言处理任务。此外,GPT-3还引入了一些新的技术,如“蒸馏”(Distillation)技术等,来提高模型的性能和稳定性。

GPT-3的原始论文是“Language Models are Few-Shot Learners”(《语言模型是一次性学习者》),于2020年发表在《自然》杂志上。该论文由OpenAI的研究人员撰写,其中包括Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan等作者。
GPT-3在各种自然语言处理任务中都表现出色,例如文本分类、命名实体识别、机器翻译、语言生成等。它也可以被用来解决很多人工智能的挑战,例如问答、自然语言对话、智能客服等。此外,GPT-3还可以进行零样本学习,即在没有任何样本数据的情况下学习并执行任务,这使得它在自然语言处理领域引起了极大的关注和兴趣。
ØInstructGPT
InstructGPT模型是由OpenAI在2022年3月发布的。该模型是基于GPT-3模型的改进版,被设计用来根据用户的指令生成自然语言文本,例如根据用户的描述生成文章、故事或诗歌等。
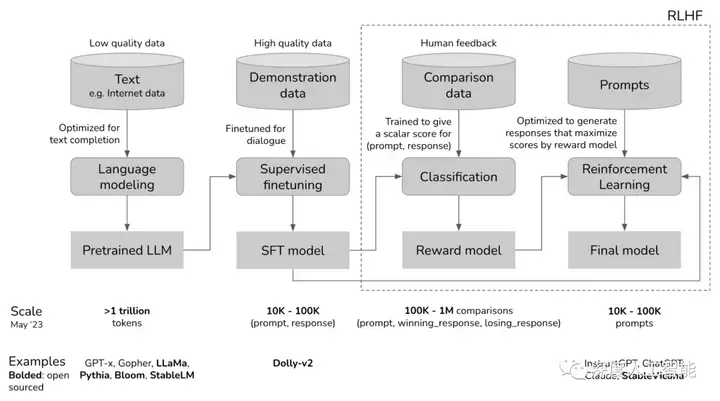
在GPT-3模型发布后,OpenAI的研究人员开始探索如何让模型更加符合人类的意图和语言规范。他们通过引入一种称为“指令重要性”(InstructionImportance)的新的损失函数,来更加注重模型对于人类指令的响应和生成。此外,他们还引入了一种称为“人工标注”(HumanFeedback)的数据集,用于训练模型对于人类意图的识别和理解。
GPT-3虽然在各大NLP任务以及文本生成的能力上令人惊艳,但是他仍然还是会生成一些带有偏见的,不真实的,有害的造成负面社会影响的信息,而且很多时候,他并不按人类喜欢的表达方式去说话。在这个背景下,OpenAI提出了一个概念“Alignment”,意思是模型输出与人类真实意图对齐,符合人类偏好。因此,为了让模型输出与用户意图更加“align”,就有了InstructGPT这个模型。
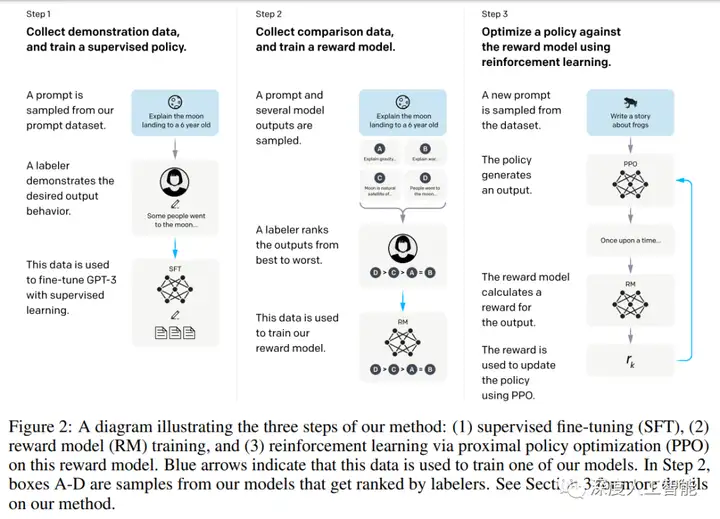
InstructGPT模型使用了一种称为“GPT-3Lite”的简化版模型架构,相比于GPT-3模型,它具有更少的参数和计算量。此外,该模型还引入了一种新的训练方法,通过结合自回归模型和生成式对话模型的特点,来提高模型的对话质量和效率。关于InstructGPT的技术方案,原文分为了三个步骤:有监督微调,奖励模型训练,强化学习训练;实际上可以把它拆分成两种技术方案,一个是有监督微调(SFT),一个是基于人类反馈的强化学习(RLHF)
GPT-3中的few-shot对于同一个下游任务,通常采用固定的任务描述方式,而且需要人去探索哪一种任务表述方式更好。显然这种模式与真实场景下用户的使用方式存在较大的gap,用户在向GPT-3提问时才不会采用某种固定的任务表述,而是随心所欲地以自己的说话习惯去表达某个需求。InstructGPT在SFT中标注的数据,正是为了消除这种模型预测与用户表达习惯之间的gap。在标注过程中,他们从GPT-3的用户真实请求中采样大量下游任务的描述,然后让标注人员对任务描述进行续写,从而得到该问题的高质量回答。这里用户真实请求又被称为某个任务的指令,即InstructGPT的核心思想“基于人类反馈的指令微调”。
InstructGPT模型的原始论文是“Training language models to follow instructions with human feedback”(《训练语言模型遵循人类反馈的指示》),InstructGPT的论文发布于2022年3月,不过OpenAI早在1月份就发布了相关博客。当时,OpenAI明确提到,InstructGPT利用了人类反馈的强化学习方法(RLHF)对GPT-3进行微调,使得该模型的输出更加符合人类偏好,这点在ChatGPT的训练中得到了延续。其中包括LongOuyang、JeffWu、XuJiang、DiogoAlmeida、CarrollL.Wainwright等作者。

InstructGPT模型的发展是基于GPT系列的研究和开发,通过引入新的损失函数、新的数据集和新的训练方法,来提高模型的对话质量和效率,使其更加符合人类的意图和语言规范。
ØGPT-3.5
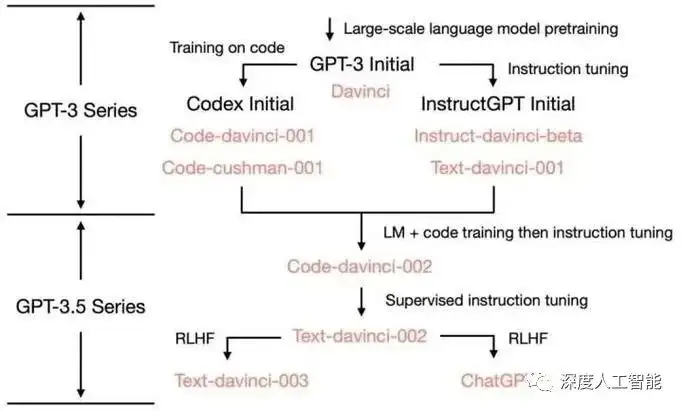
GPT-3.5系列模型是GPT-3的微调版本,从 2021 年第四季度开始就使用文本和代一起进行训练。以下模型属于 GPT-3.5 系列:
lcode-davinci-002 是一个基础模型,非常适合纯代码完成任务
ltext-davinci-002 是一个基于 code-davinci-002 的 InstructGPT 模型
ltext-davinci-003 是对 text-davinci-002 的改进
lgpt-3.5-turbo-0301 是对 text-davinci-003 的改进,针对聊天进行了优化
GPT-3.5的发展路线是基于GPT系列的研究和开发。在GPT-3模型发布后,OpenAI的研究人员开始探索如何让模型更加符合人类的意图和语言规范。他们通过引入一种称为“指令重要性”(InstructionImportance)的新的损失函数,来更加注重模型对于人类指令的响应和生成。此外,他们还引入了一种称为“人工标注”(HumanFeedback)的数据集,用于训练模型对于人类意图的识别和理解。
GPT-3.5的相关论文是“Augmenting Reinforcement Learning with Human Feedback”(《利用人类反馈增强强化学习》),GPT3.5与 GPT-3 的主要区别在于,新加入了被称为 RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习)。这一训练范式增强了人类对模型输出结果的调节,并且对结果进行了更具理解性的排序。
GPT-3.5的发展是基于GPT系列的研究和开发,通过引入新的损失函数、新的数据集和新的训练方法,来提高模型的对话质量和效率,使其更加符合人类的意图和语言规范。GPT-3.5模型相比于GPT-3模型,它具有更少的参数和计算量。此外,该模型还引入了一种新的训练方法,通过结合自回归模型和生成式对话模型的特点,来提高模型的对话质量和效率。
与GPT-3相比,GPT-3.5在模型结构和训练方法上都有所创新。在模型结构方面,GPT-3.5增加了更多的层数和参数,从而使模型的表示能力更强,能够更好地处理复杂的自然语言任务。在训练方法方面,GPT-3.5采用了更加先进的自监督学习方法,能够更好地利用大量的未标注数据进行训练,从而提高模型的泛化能力。目前OpenAI官网免费开放使用的版本也是GPT3.5。
ØChatGPT
ChatGPT是在2022年初完成训练的GPT-3.5系列的基础上进行微调的。ChatGPT和GPT 3.5在Azure AI超级计算基础设施上进行了训练。ChatGPT具备强大的自然语言处理能力,可以像人类一样进行对话,并根据对话内容进行智能回复。与传统的聊天机器人不同,它们的设计目的、模型规模、应用场景等方面都有所不同。ChatGPT的回答更加自然、流畅,可以模拟人类的对话风格。
根据OpenAI官网的介绍,ChatGPT是InstructGPT的兄弟模型,后者经过训练,可以遵循提示中的指示并提供详细的响应。OpenAI使用来自人类反馈的强化学习(RLHF)训练ChatGPT模型,使用与InstructGPT相同的方法,但在数据收集设置上略有不同。首先使用监督微调训练了一个初始模型:人类人工智能训练师提供对话,他们在其中扮演双方——用户和人工智能助手。然后提供模型撰写的建议,以帮助撰写回答。我们将这个新的对话数据集与 InstructGPT 数据集混合,并将其转换为对话格式。
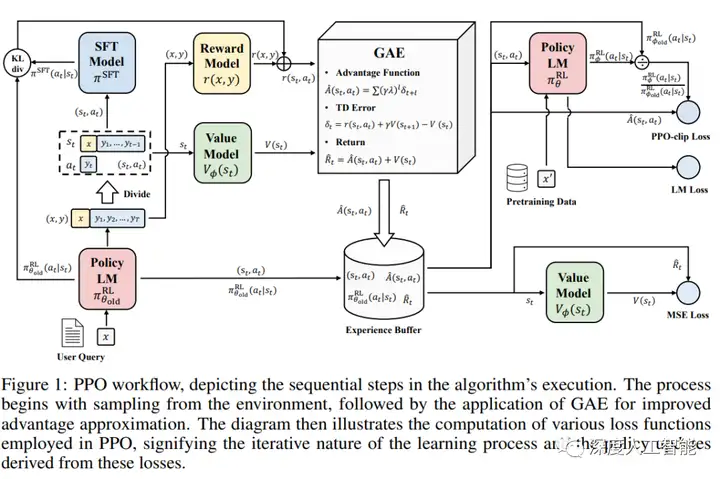
为了创建强化学习的奖励模型,需要收集比较数据,其中包括两个或多个按质量排名的模型响应。为了收集这些数据,工程师进行了人工智能培训师与聊天机器人的对话。然后随机选择了一个模型编写的消息,抽样了几个轮次完成,并让AI培训师对它们进行排名。使用这些奖励模型,可以通过以下方式微调模型近端策略优化.我们执行了此过程的多次迭代。
ChatGPT 有时会给出似是而非但不正确或荒谬的答案。解决此问题具有挑战性,因为:
l在 RL 培训期间,目前没有事实来源;
l训练模型更加谨慎,导致它拒绝可以正确回答的问题;
l监督训练误导了模型,因为理想的答案取决于模型知道什么,而非人类演示者所知道的。
ChatGPT 对调整输入措辞或多次尝试相同的提示很敏感。例如,给定一个问题的措辞,模型可以声称不知道答案,但稍微改写提示一下,就可以正确回答,这也是源于ChatGPT的prompting机制。
理想情况下,当用户提供不明确的查询时,模型会提出澄清问题。实际目前的模型通常会猜测用户的意图。
虽然使用者可以使模型拒绝不适当的请求,但它有时还是会响应有害指令或表现出有偏见的行为。目前OpenAI正在使用审核接口警告或阻止某些类型的不安全内容,但目前任然有一些漏报和误报。

下面是ChatGPT 相关的论文:
1、《Interactively Shaping Agents via Human Reinforcement》:ChatGPT 中的 TAMER(Training an Agent Manually via Evaluative Reinforcement,评估式强化人工训练代理)框架,将人类标记者引入到 Agents 的学习循环中,可以通过人类向 Agents 提供奖励反馈(即指导 Agents 进行训练),从而快速达到训练任务目标。
2、《Proximal Policy Optimization Algorithms》:PPO(Proximal Policy Optimization,近端策略优化)强化学习模型,是 ChatGPT 训练的第三阶段。
3、《Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers:What learning algorithm is in-context learning? Investigations with linear models》
4、《What learning algorithm is in-context learning? Investigations with linear models》:ChatGPT 训练时的输入使用的是 Prompt,Prompt 是研究者们为了下游任务设计出来的一种输入形式或模板,它能够帮助预训练模型“回忆”起自己在预训练时“学习”到的东西。
ØGPT-4
GPT-4是OpenAI在2023年3月14日正式发布的新模型,根据OpenAI官方博客的介绍,GPT-4在许多方面都表现得比ChatGPT更加优秀,包括更强的创造力、更准确的对话理解、更丰富的多任务能力和更全面的性能提升。

与ChatGPT 相比,GPT-4采用了更复杂的模型架构和更多的参数,以应对自然语言处理任务的日益复杂性和多样性。此外,GPT-4还采用了更广泛的数据集和更多的训练数据,以增加模型的泛化和适应能力。另外,GPT-4还引入了强化学习和其他先进的技术,以进一步优化模型的性能和对话质量。
GPT-4是在GPT系列模型的基础上不断发展和迭代而来的,其发展路线包括不断增加模型参数、改进模型结构、采用更多的训练数据和引入先进的技术等。随着技术的不断进步和发展,相信GPT-4将会在未来的自然语言处理领域发挥更加重要的作用。

GPT4是一个大型的多模态模型,虽然在许多现实世界场景中的能力不如人类,但在各种专业和学术基准上表现出人类水平的表现。例如,它通过模拟律师考试,分数在应试者的前 10% 左右;相比之下,GPT-3.5 的得分在倒数 10% 左右。OpenAI花了 6 个月的时间,使用对抗性测试程序和 ChatGPT 的经验教训迭代调整 GPT-4,从而在真实性、可控性和拒绝超出回答边界方面取得了有史以来最好的结果(尽管远非完美)。
GPT-4是一个基于transformer的预训练模型,用于预测文档中的下一个标记。训练后的调整过程会提高对事实的衡量和对期望行为的坚持。这个项目的一个核心组成部分是开发基础设施和优化方法,这些方法可以在大范围内预测行为。GPT4目前是收费使用。
GPT-4和GPT-3.5对比来看,有以下几个区别:
l在处理复杂任务上,GPT-4更可靠、更有创意,并且能够处理更细微的指令。
l各种奥林匹克竞赛、GRE考试、代码考试、统一律师考试等测试上,GPT-4都基本完胜GPT-3.5。
l在机器学习的一些基准测试集上,也表现更加突出,达到了SOTA的水准,比大部分的语言模型效果要好。
GPT-4到目前为止并没有发布过多的技术细节,以下是相关的报告和论文:
1、《GPT-4 Technical Report》:本报告主要介绍GPT-4的功能、限制和安全特性。GPT-4是一个transformer风格的模型预训练,用于预测文档中的下一个令牌,使用公开可用数据(如互联网数据)和第三方提供商授权的数据。然后使用来自人类反馈的强化学习(RLHF)对模型进行微调。考虑到竞争格局和大型模型(如GPT-4)的安全影响,本报告没有包含有关架构(包括模型大小)、硬件、训练计算、数据集构造、训练方法或类似内容的进一步细节。
2、《Sparks of Artificial General Intelligence: Early experiments with GPT-4》 :3月22日,微软发布了一篇长达154页的论文《Sparks of Artificial General Intelligence: Early experiments with GPT-4》,公布对GPT-4展开的全面能力测试结果。在涉及语言、数学、编码、视觉、医学、法律、心理学等跨领域任务中,不需要任何特别提示,GPT-4就能完成任务。
“GPT-4语言模型可以被视为AGI(Artificial General Intelligence,通用人工智能)的早期版本。”微软研究院的研究人员在论文结尾说。
ØLLaMA
LLaMA(Large Language Model Meta AI),由 Meta AI 发布的一个开放且高效的大型基础语言模型,共有7B、13B、33B、65B(650 亿)四种版本。其数据集来源都是公开数据集,无任何定制数据集,保证了其工作与开源兼容和可复现,整个训练数据集在 token 化之后大约包含 1.4T 的 token。
关于模型性能,LLaMA 的性能非常优异:具有 130 亿参数的 LLaMA 模型「在大多数基准上」可以胜过GPT-3( 参数量达 1750 亿),而且可以在单块 V100 GPU 上运行;而最大的 650 亿参数的 LLaMA 模型可以媲美谷歌的 Chinchilla-70B 和 PaLM-540B。
关于训练集,其来源都是公开数据集,无任何定制数据集,保证了其工作与开源兼容和可复现。整个训练数据集在 token 化之后大约包含 1.4T 的 token。其中,LLaMA-65B 和 LLaMA-33B 是在 1.4万亿个token 上训练的,而最小的模型 LLaMA-7B 是在 1万亿个 token 上训练的。
随着Meta开源的7B——65B LLaMA大模型的发展,激发了各大AI企业打造类ChatGPT的热情,并由此衍生出Alpaca、Vicuna、ColossalChat等微调项目。
但LLaMA只开源了模型权重且限制商业使用,微调能够提升和注入的知识与能力也相对有限。对于真正投身大模型浪潮的企业来说,仍必须预训练自己的核心大模型。
为此,开源社区也做了诸多努力:
RedPajama:开源可商用类LLaMA数据集,无训练代码和模型
OpenLLaMA:开源可商用类LLaMA 7B, 13B模型,使用EasyLM基于JAX和TPU训练
Falcon:开源可商用类LLaMA 7B, 40B模型,无训练代码
继LLaMA开源后,Meta今天联手微软高调开源Llama 2,一共有7B、13B、70B三个版本。Llama 2接受了2万亿个token训练,上下文长度4k,是Llama 1的2倍。微调模型已在超100万个人类标注中进行了训练。
Llama 2的表现更是秒杀许多开源语言模型,在推理、编码、能力和知识测试上取得了SOTA。
据说Llama 2不仅可以研究,甚至能免费商用!
Llama-2相比Llama-1有不少技术层面的改进,从而带来了模型性能、推理效率以及安全性等方面的有效提升。具体而言,重要的改进有以下几点:
Llama 2 模型接受了 2 万亿个标记的训练,上下文长度是 Llama 1 的两倍。Llama-2-chat 模型还接受了超过 100 万个新的人类注释的训练。
Llama 2训练语料相比LLaMA多出40%,上下文长度是由之前的2048升级到4096,可以理解和生成更长的文本。
从人类反馈中强化学习,除了Llama 2版本,还发布了LLaMA-2-chat ,使用来自人类反馈的强化学习来确保安全性和帮助性。
LLaMA系列论文:
1、《LLaMA: Open and Efficient Foundation Language Models》
2、《LLaMA 2: Open Foundation and Fine-Tuned Chat Models》
ØChatGLM
ChatGLM 是由清华大学 KEG 实验室和智谱 AI 公司于 2023 年共同训练的语言模型 ,它采用了深度学习技术,能够对自然语言文本进行建模,并且具备语言生成和对话的能力。
ChatGLM 是一个基于千亿基座模型 GLM-130B 开发的对话机器人,具有问答、多轮对话和代码生成功能。目前,ChatGLM有两个版本:千亿参数的 ChatGLM(内测版)和 62 亿参数的 ChatGLM-6B(开源版)。ChatGLM-6B 是在2023年3月14日正式开源的,结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM 的技术基础是 GLM-130B,这是一个包含多目标函数的自回归预训练模型,同时支持中文和英文,并且在多个自然语言处理任务上优于其他千亿规模的模型。
ChatGLM 的性能表现也十分出色。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。而千亿参数的 ChatGLM 则更进一步,在问答和对话方面具有更强大的能力。例如,ChatGLM 可以根据用户提供的主题和语言来生成不同风格和内容的文本,也可以根据用户提供的代码需求来生成相应的代码片段。此外,在开源社区作者的加持下,基于ChatGLM-6B的变种项目还可以处理图像输入,实现图像理解和多模态对话。
ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型ChatGLM,ChatGLM2-6B的推理速度提升了42%,上下文长度由2K扩展到了32K,在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升。ChatGLM2对学术研究完全开放,允许申请商用授权。
除此之外,ChatGLM2-6B能够生成更长的上下文,基于 FlashAttention 技术,将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。以及实现了更高效的推理,基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用,在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
ChatGLM系列论文:《GLM: General Language Model Pretraining with Autoregressive Blank Infilling》
Ø其他
关于AIGC领域的大模型、以及GPT系列的开源模型还有很多,比如谷歌已经发布的多模态模型PaLM1、PaLM2,和谷歌旗下DeepMind团队正紧锣密鼓在准备的Gemini模型,据说近期即将发布,Gemini模型将合并AlphaGo和GPT-4等大模型的语言功能,旨在赋予系统新的能力,如规划或解决问题,并力求超越OpenAI的GPT-4模型,听着都很激动。DeepMind前创始人之一也发布了自己新公司的Inflection模型,该模型是由Google人工智能实验室DeepMind的创始人之一的Mustafa Suleyman创办,公司仅仅成立一年多的时间,就形成如此局面,足以看出Inflection强劲实力。而且Inflection已自OpenAI、DeepMind和Google找来许多过去曾协助打造语言模型的AI专家,目前的团队已达到35人,科研团队实力强劲。还有阿联酋阿布扎比的技术创新研究所(TII)近期刚发布的具有1800多亿参数的Falcon模型,通过3.5万亿token训练,性能远超Llama2,堪比GPT4。最大的模型是40B,在AWS上384个GPU上训练了两个月,中东土豪真的是不缺钱啊。最后这个模型还直接免费给大家商用了,不得不说这格局打开了就是不一样啊。

除了以上的通用大模型之外,还有一些专用大模型也发展迅速,比如专攻数学方向的MathGPT;专攻医疗方向的MedGPT;还有专攻代码方向的CodeGPT、CodeLlama模型,以及其他各领域的专用模型。想必未来专用大模型的发展和应用会远超通用大模型,不要问为什么,想一想人类的发展就清楚了,没有人会是完全的通才,模型的发展也一样,MathGPT做数学肯定比ChatGPT强,CodeGPT写代码也肯定比ChatGPT强。未来ChatGPT的这类通用模型在实际应用中的比例将会逐渐下降,会被各类专用模型替代,想要在一个领域发展的更好,就需要专才,而非通才。
本文只对常见的一些模型做了简单介绍,梳理了一下GPT的发展路线和各个版本的区别,至于更加详细的技术内容,我们将会在后期的文章和课程中持续更新,欢迎大家关注!













