智谷炼药师协会学徒
炼丹药的迷惑
相信各位丹友在炼丹期间都会遇到各种各样的问题,有些问题查查资料,做做实验就解决了,有些问题可能还是需要等大佬们去解决。本人在炼丹期间,就遇到了一个问题,这里简单分享一下,一般我们训练模型的时候,选择一个较大的Batch加载训练数据是一个高效训练的方法,当然也不是说Batch越大就越好,一个合适的Batch size对于模型训练才是最好的选择。如果输入是高分辨率图像的时候,由于显存的限制,batch就会变得很小,而且GPU显存总是告急,但是GPU计算资源却大量冗余。如何在加载大分辨率图像的时候增大Batch,有效的利用计算资源,是我们需要解决的问题。

一般当图像分辨率较小的时候,我们不会过于担心训练过程中Batch size的设置问题,由于图像分辨率较小,加载较大Batch不会出现显存不够用的情况,但是当遇到较大分辨率的图片做为训练数据的时候,情况就不一样了,这时候往往会需要更大显存来加载数据,模型训练中一般会出现一次加载的Batch极度变小的情况,这无疑加大了模型的训练时间,对于加了BN层的模型来说还会影响到训练效果。比如在训练YOLO模型的时候,当图像的大小达到了640*640,在6G的显存上一次只能加载几张图片。而对于训练一个泛化性能较好的模型,往往需要更大的数据集来学习,一边是捉襟见肘的显存,一边是更大的训练数据集,显而易见,扩大显存已经是迫在眉睫。
增加显存最好的方法,是更换更大显存的GPU,但是这种从硬件上直接下手的方法不是谁都有这个资本的,毕竟显卡是用真金白银换来的,所以最好办法是从模型上下手去操作。我们在训练大分辨率的图像数据的时候,最容易出现的情况就是一边是显存溢出,一边算力闲置。
所以联想到能否以闲置的计算资源来换取匮乏的显存呢?其实大佬们早以为我们提供了方法。
大批量的炼药方法
2020年6月17日发布的论文《Dynamic Tensor Rematerialization》全面论述了以计算资源换取显存的可行性。该论文在此后的时间了进行了几次改进,直到2021年3月18日出现了V4版本,论文也提供了pytorch中的使用方法。
论文介绍中也简单的阐述了基本的实现思路:
检查点通过从内存中释放中间激活并按需重新计算它们,可以在有限的内存预算下训练深度学习模型。当前的检查点技术静态地计划这些离线重新计算并假设静态计算图。我们证明了一个简单的在线算法可以通过引入动态张量重新实现(DTR)来实现可比的性能,这是一种用于检查点的贪婪在线算法,具有可扩展性和通用性,由驱逐策略参数化,并支持动态模型。我们证明了 DTR 可以训练一个N-层线性前馈网络 Ω (N--√) 内存预算只有 O (N)张量运算。DTR 与模拟实验中最佳静态检查点的性能密切匹配。我们仅通过插入张量分配和运算符调用并收集有关张量的轻量级元数据,将 DTR 原型合并到 PyTorch 中。
基本操作就是使用GPU的计算资源换取神经网络每次前向传播过程中的部分中间缓存值,简而言之,就是以GPU的计算力换取GPU的显存空间,从而加载更大的batch。具体做法就是释放模型中的部分前向激活输出值,等后向传播的时候再从当前节点的上一层重新计算一次该层的输出,而不是一直保存在显存中,这样就等于提前释放了这部分显存空间,等下一次加载新的数据的时候就可以加载更大的batch。
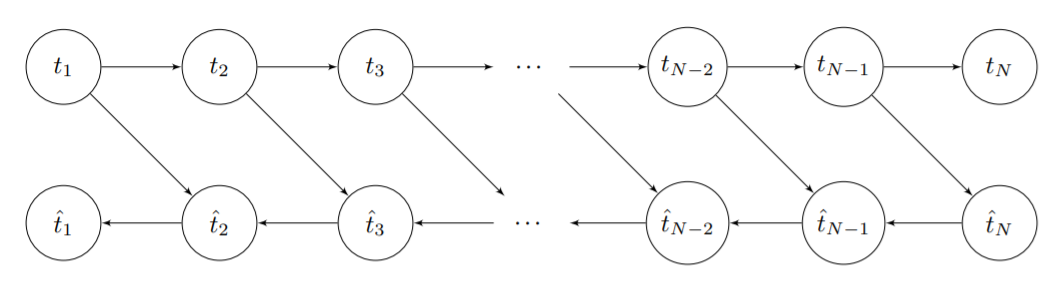
下图是正常的模型前向和后向运行过程中每个节点的张量释放情况:
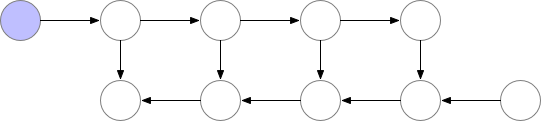
下图是使用了以计算资源来换取显存后的模型每个节点的张量释放情况:
关于释放哪一部分缓存值才是最高效的替代方法,也有一定的讲究。具体来说满足以下三个需求即可:
①被释放后需要重新计算的张量对于GPU的开销越小越好
②被释放的张量占用的显存越大越好
③被释放的张量在显存中占用的时间越长越好
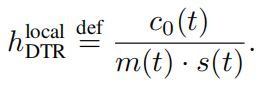
H localDTR为被释放的最优张量;C0(t)为重新计算张量时该算子运行的时长,运行时间越短对于GPU的开销越小;s(t)是张量进入显存的时长,越长越好;m(t)是张量占用的内存,越大越好。
我们的模拟显示了在合理的计算开销上的显著节省。虽然由于混叠和变异的复杂性,我们无法实现现有的静态检查点方案作为基线(特别是在动态模型中),但我们注意到,与专家手工修改模型相比,这些结果节省了类似数量的内存。例如,一个手动优化的DenseNet-BC模型[27]在降低25.5%的情况下实现了56.1%的内存消耗,而我们使用DTR-EqClass的模拟试验产生了20.0%的内存消耗,开销22.7%。尽管这些数字并不具有直接的可比性,因为模拟不包括动态分析开销,但它们说明了DTR(使用适当的启发式)可以实现内存计算的折衷,否则就需要专家进行干预。此外,与现有的静态方法不同,DTR在具有任意动态性的模型上自动节省内存,尽管它开始在LSTM和TreeLSTM的较低预算上大打折扣。在所有情况下,结果表明,更复杂的启发式方法可以通过更低的操作符开销获得更好的内存节省,尽管这些复杂的启发式方法也引入了更多的运行时开销,这在DTR的实现中必须加以考虑。值得注意的是,即使是最不复杂的启发式算法,如LRU(需要非常少的运行时开销),也可以在抖动之前用非常少的开销实现高达30%的内存节省,这表明检查点可以很容易地获得一些内存节省。
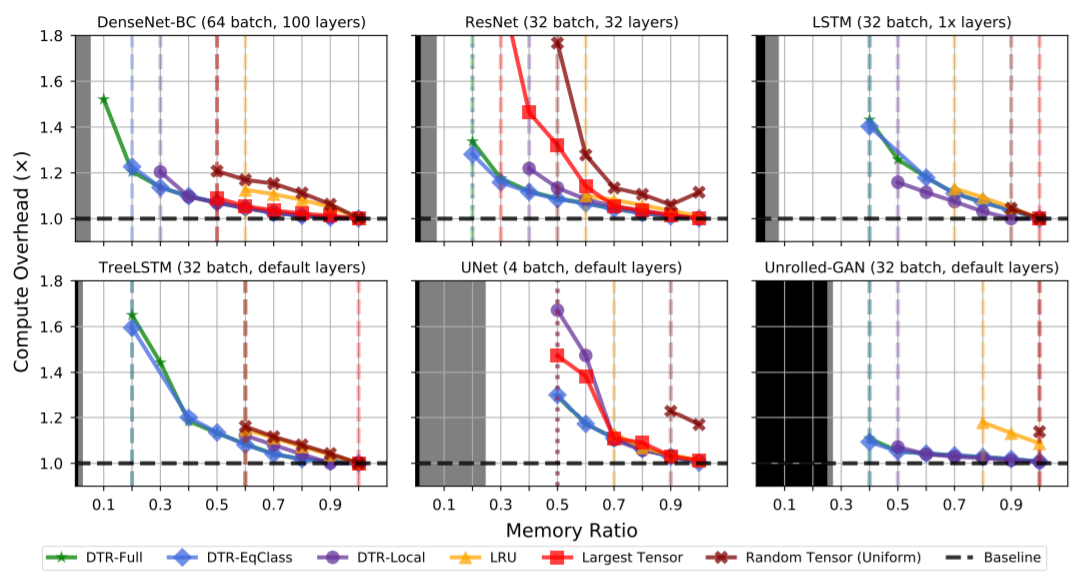
论文中比较了不同模型上的不同方法,比较了不同预算(原始峰值内存使用量的一小部分)的计算减速率。每个图中的黑色区域对应于存储输入和权重所需的内存,而灰色区域表示需要同时使用最多内存的单个操作符。虚线和虚线分别表示抖动和内存不足错误之前的最后一个比率。
以下是论文中对于使用DTR前后的显存情况对比:
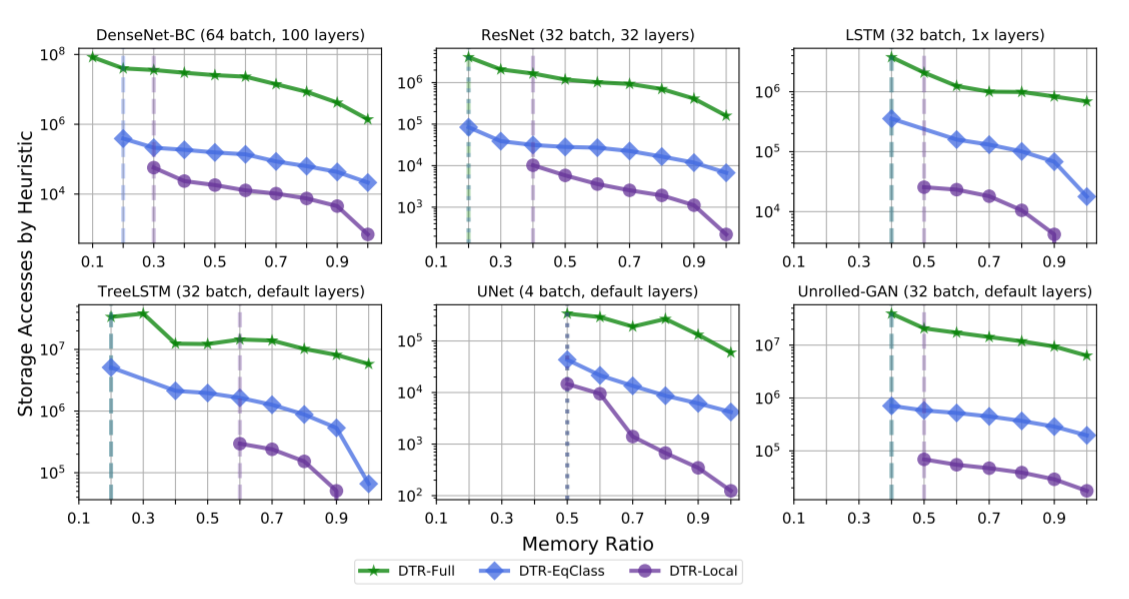
此外,论文中还提出了DTR的三种变种体:DTR-Full、DTR-EqClass、DTR-Local,对于3种主要hDT R变体,通过不同的内存比率比较启发式评估和元数据维护引起的总存储访问。
关于tensorflow和pytorch上的使用方法:https://github.com/merrymercy/dtr-prototype
最后祝大家在炼丹的路上越走越好,有什么好的方法也可以互相讨论。













