在上一篇文章《深度学习之数据处理方法概述》中,我们介绍了深度学习中数据处理的方法,其中提到了数据标准化的方法,没有进行详细介绍,这篇文章主要就是针对数据标准化的方法的介绍,希望让大家对数据标准化的理解和使用有一定的帮助。本文发布于深度人工智能订阅公众号原创文章,转载请注明来源,我们长期致力于传播人工智能知识,发展深度人工智能教育。

一、什么是数据标准化
1、数据标准化概念
数据标准化,顾名思义,就是将原来分布范围不同的数据缩放在一个范围之内,一般来说是标准化到均值为0,标准差为1的标准正态分布,均值为0是为了让数据中心化,让各个维度的特征都平衡,标准差为1是为了让数据在各个维度上的长度都呈现一个单位向量(矩阵),也就是把原来大小范围分布不通的数据缩放成统一量纲,和拳击比赛一样,只有相同重量级的对手才能同台比赛,这里把数据的标准差缩放为1的意义就相当于把轻量级选手的体重加重,把重量级选手的体重减轻,让他们在同一个擂台上比赛,否则比赛就不公平。
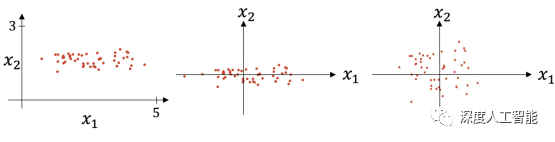
在以深度学习为主的人工智能项目的实现过程中,对数据的数量和质量的要求都极高,一般来说,原始数据可以通过各种不同的渠道去收集,最终能够得到大量的数据,为了加快训练,消除对训练不利的因素,往往会使用数据标准化的方法来处理数据。

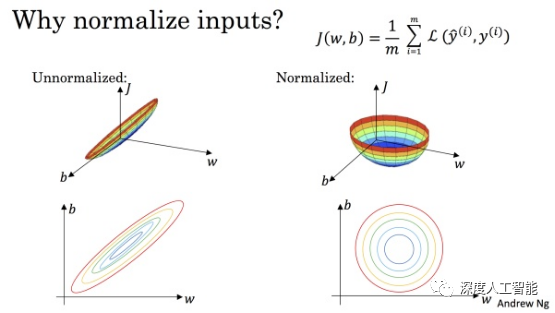
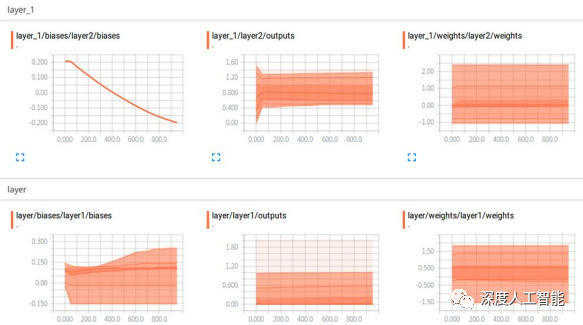
一般在现实环境中获取到的数据,质量往往很难保证。很多收集来的原始数据中实际上是包括了很多噪声数据的,这个时候就需要对数据进行去噪处理,除了去噪处理,一般还会对数据进行标准化处理,而数据的标准化处理,不仅仅指的是在数据输入模型前的标准化处理,在数据输入模型后,在对模型中每一层的输出数据也要标准化处理。可以借助tensorboard工具观察网络模型中每一层的输出结果和权重分布是否在允许的范围内,一般经过标准化处理后的数据,每一层的输出都是固定在一定范围内的。
2、数据标准化指标
既然要对数据标准化处理,那么就需要提出标准化的指标是什么,一般来说,对于从实际环境中获取来的数据,我们会根据数据是否具有明显的界限分为有界数据和无界数据,有界数据就是有着明确的数据边界,也就是数据是固定的,无界数据就是没有明确数据边界,也就是说数据是有可能会改变的。
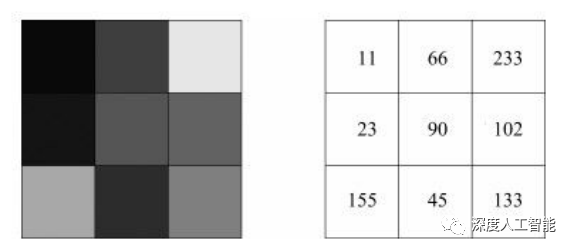
对于有界数据的标准化方法,由于数据的边界是固定的,显然会和数据的数量以及最小值、最大值有关系,所以一般会将原数据与数据数量大小、最小值及最大值进行计算操作,从而将数据按照一定的比例缩放在一定的范围内。对于有界数据的标准化方法相对来说比较简单,在实际的项目中我们处理的大部分数据也都是固定的数据,既然数据是固定的,那么也就有有界的了。比如对图像数据处理将[0,255]之间的数据处理到[-1,1]之间,符合了均值为0和标准差为1的标准,就是对有界数据进行固定的缩放。
无界数据是指数据的边界不一定是固定的,也就是数据的边界不确定,随时有可能发生变化,或者不知道数据的边界,这类数据主要是使用均值方差的方法标准化,实际上也很容易想象得到,同一个均值方差下的不同数据集,只能证明这些数据集统计出的均值和方差是一样的,也就是说明它们的分布是一样的,但是并不代表它们的数量是一致的,就像从标准正太分布当中采样一样,你可以采集100个样本,也可以采集200个、300个......,无论你采集多少数量的数据,它们的分布都是一样的,也就是均值和方差都一样,都是从N[0,1]中采样。
二、数据标准化的作用
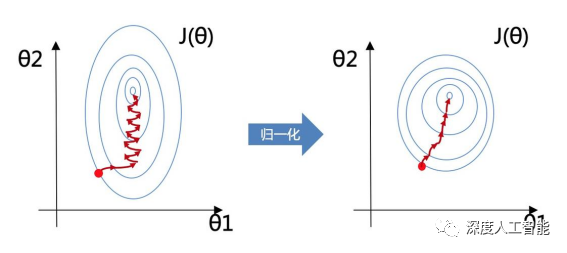
1、统一量纲,平滑不同批次和不同层数据间的梯度,防止模型梯度爆炸或者梯度弥散
数据标准化后,由于原数据的数值被缩放在较小的范围之内,其原来数据之间的“梯度鸿沟”也会被整体缩小,起到了平滑梯度的作用,能够防止模型中某一层的数据出现大的震荡,不利于训练。因为数据震荡过大,会导致其要训练的各种参数的导数变化也会增大,而对于求导而言,当然是越平滑越好,那么我们希望的就是模型的每一层输出都不要发生剧烈的震荡,最好的办法就是对模型每一层的输出都进行标准化处理,将其缩放在一定范围内,这样在模型反向传播求导的时候,模型的损失也会趋于平稳,不容易出现梯度爆炸或者梯度消失的问题。
2、消除奇异数据(离群点)对模型训练的负面影响,加快收敛速度
奇异数据就是在原数据结构中方差较大的数据,在数轴上的表现就是远离其他样本数据,由于在以深度学习为主的梯度下降法中,对于模型的输出和标签之间所求的损失误差,通过计算均值得到的一个平均误差,因此使用梯度下降法反向传播梯度的时候,也是通过这个均值误差来更新各项参数的,由此我们可以判断,模型最终的均值误差对于模型的效果有着举足轻重的影响,而影响均值误差的因素就是所有误差了。

比如模型加载的批次是100,也就是每次加载100个数据去训练,那么每一批次的训练都会得到100个输出,同样会有100个误差,而这100个误差最终是通过计算均值得到一个均值误差的,想要保证均值误差能够体现真正的数据分布误差,就要考虑到每个误差都不能偏离均值太远,但是实际情况却恰恰相反,在采集到的原始数据中,往往会存在各种远离数据均值的奇异数据,这些奇异数据的误差往往会更大,直接会将损失拉的更高,由于损失下降对针对均值损失而言,只有所有损失的方差都在一定范围内,才会达到损失平稳快速下降的目的,但是奇异数据产生的异常点损失会让均值损失无法平稳快速的下降,还会容易让损失产生一定震荡。
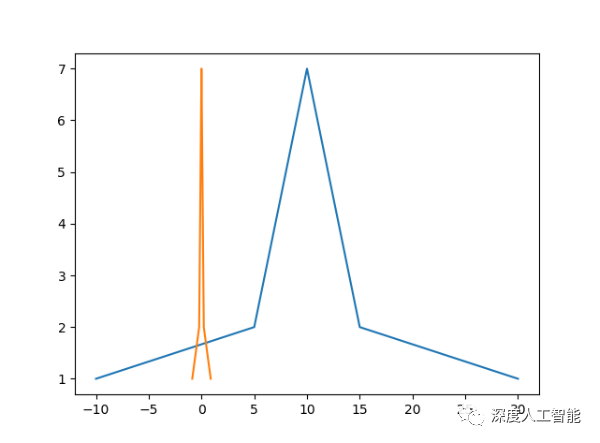
在数据做了标准化后,会将奇异数据的所产生的误差缩小,让损失能够稳定快速地下降。此外还可以通过四分位法,通过删除原始数据中的中位数,只截取排序后数据中25%到75%之间的数据来去除奇异数据,然后再对剩余的数据做标准化,这样的效果会更好。只不过这种操作要确定数据中确实存在奇异数据才比较好用,否则会截除掉正常数据导致数据的数量变少。
3、消除噪声数据对模型的负面影响,防止模型过拟合
数据标准化可以降低噪声数据对于模型输出结果的影响,一般来说,数据通过标准化处理,能够去除量纲干扰,利用小波降噪处理去除随机噪声。由于噪声一般属于高通滤波,数据标准化在一定程度上可以起到平滑梯度的作用,而噪声一般周围其他数据间的梯度往往较大,使用了数据标准化处理,能够降低它们之间的梯度,从而达到消除噪声的效果。
当然对于数据去噪,我们不能依赖于数据标准化,数据标准化的最主要作用还是统一量纲,加快训练速度,至于去噪,只是附带作用,如果要真正的对数据做去噪处理,不妨尝试使用低通滤波的方法,去除掉数据中高通部分,只留下低通和中通部分数据即可,比如高斯滤波、中值滤波、基于傅里叶变换的低通滤波等等。

严格来说,原数据中包含少量的噪声对于模型训练是有益的,能够提高模型的泛化能力,因为噪声数据可能拟合了现实世界中的各种不同的场景;如果原始数据包括了大量的噪声数据,甚至于噪声数据的占比已经超过了一定的范围,则是对训练无益的,因为噪声数据过大,说明采集的原数据和现实数据的偏差也过大,模型学到的分布和现实数据的分布也不一样了,相当于是另一个数据分布了。
三、数据标准化的方法
1、最大值标准化
最大值标准化就是让数据中的每个值都除以最大值,把数据缩放到[0,1]之间:x=x/max(x),这种方法适合数据都是正数的情况,比如图像像素是[0,255]之间的正数,让每个像素值都除以255,就可以把图像像素值归一化到[0,1]之间,还可以对归一化后的数据再减去均值,除以标准差,规范到[-1,1]之间:x=(x-0.5)/0.5。
2、绝对最大值标准化
上面介绍的最大值标准化方法主要是针对正数而言,如果数据中包括了负数,使用上面的方法就无法保证数据被缩放到[-1,1]之间,这个时候我们需要先对数据取绝对值,然后再进行最大值标准化把数据缩放到[0,1]之间:x=x/max(abs(x)),如此便能消除负数太小带来的影响。
3、最大最小值标准化
最大最小值标准化是利用数据的最大最小边界值来标准化数据,具体操作就是让每一个数据都减去最小值,然后除以最大值减去最小值的结果,将数据缩放到[0,1]之间:x=(x−min(x))/(max(x)−min(x)),根据公式,可以发现,如果当前数据为最小值,则分子为0.此时,标准化的结果也为0,反之如果当前数据为最大值,则分子与分母相等,标准化的结果为1,可见此方法无论数据为正数还是负数都能够将数据缩放到[0,1]之间。
4、均值方差标准化
均值方差(标准差)标准化是最为常用的数据标准化方法,操作过程就是让每个数据都减去均值,然后除以标准差:x=(x-mean(x))/sqrt(x-mean(x)**2),目的是将数据缩放到均值为0,标准差为1的标准正态分布N[0,1]。
5、范数标准化
范数标准化就是让当前数据除以当前维度上各个数据的范数之和,比如L1范数标准化就是让当前数据除以当前维度上所有数据的绝对值之和:x=x/sum(abs(x)),L2范数标准化就是让当前数据处理当前维度上所有数据的平方和再开方:x=x/sqrt(x**2),以此类推,可以扩展到N范数标准化。
6、四分位法标准化
四分位范围(RobustScaler)缩放法是使用该缩放器删除数据中的中位数,并根据百分位数范围(默认值为IQR:四分位间距)缩放数据。 IQR是第1个四分位数(25%)和第3个四分位数(75%)之间的范围。也就是去除数据中小于25%和大于75%的数据,这对异常噪声数据的处理非常有益。
四
PyTorch中的数据标准化
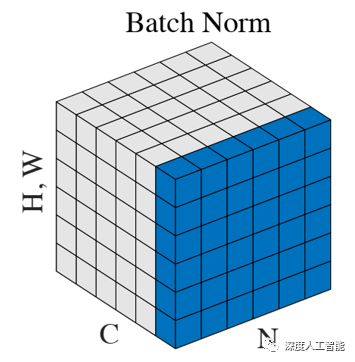
1、BN(Batch Normalization):
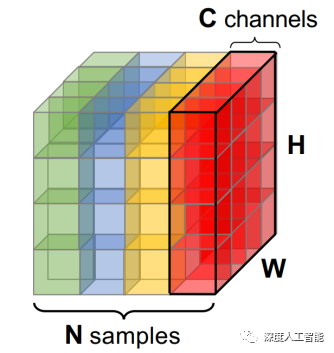
BN的计算就是把每个通道的NHW单独拿出来归一化处理,针对每个channel我们都有一组γ,β,所以可学习的参数为2*C,当batch size越小,BN的表现效果也越不好,因为计算过程中所得到的均值和方差不能代表全局。在pytorch中调用torch.nn.BatchNorm2d(out_channels)来实现。
2、LN (Layer Normalizaiton):
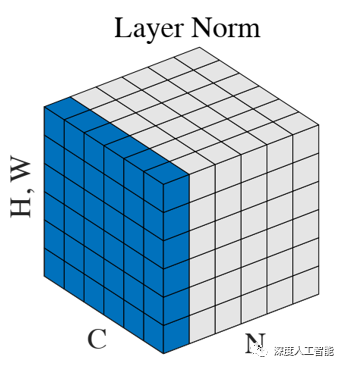
LN的计算就是把每个CHW单独拿出来归一化处理,不受batchsize 的影响。常用在RNN网络,但如果输入的特征区别很大,那么就不建议使用它做归一化处理。在pytorch中调用torch.nn.LayerNorm(out_channels,H,W)来实现。
3、IN(Instance Normalization):
IN的计算就是把每个HW单独拿出来归一化处理,不受通道和batchsize 的影响常用在风格化迁移,但如果特征图可以用到通道之间的相关性,那么就不建议使用它做归一化处理。在pytorch中调用torch.nn.InstanceNorm2d(out_channels)来实现。

4、GN(Group Normalizatio):
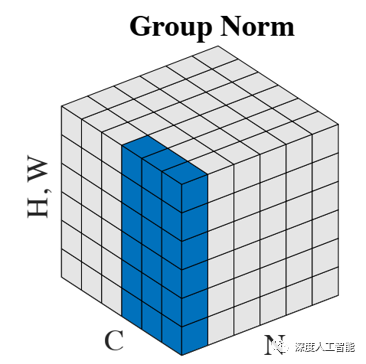
GN的计算就是把先把通道C分成G组,然后把每个gHW单独拿出来归一化处理,最后把G组归一化之后的数据合并成CHW。GN介于LN和IN之间,当然可以说LN和IN就是GN的特列,比如G的大小为1或者为C。在pytorch中调用torch.nn.GroupNorm(num_groups,out_channels)来实现。
5、SN(Switchable Normalization):
将 BN、LN、IN 结合,赋予权重,让网络自己去学习归一化层应该使用什么方法。集万千宠爱于一身,但训练复杂。
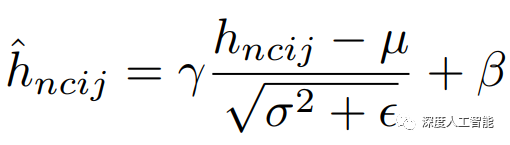
本文内容由深度人工智能公众号原创提供,转载或摘录请联系作者注明来源!
深度人工智能教育是成都深度智谷科技旗下的教育信息平台,我们会为人工智能学习者呈现最实用的干货技能,也会为人工智能从业者考取人工智能相关的证书提供报考服务,有意者可以联系我们。













