一、大模型的发展背景
谈起大模型,第一时间想到的是什么?是主流的ChatGPT?或者GPT4?还是DALL-E3?亦或者Midjourney?以及Stablediffusion?还是层出不穷的其他各类AI Agent应用工具?大模型在2023年突然遍地开花,井喷式发展,尤其是后半年,几乎大部分科技公司、学术团体、研究机构、以及学生团队都在发布各自的大模型,感觉大模型突然从洛阳纸贵到了唾手可得。

大模型能在短时间内层出不穷的原因不仅是因为国外开源的LLaMa2、Falcon等,以及国内开源的ChatGLM、Baichuan2等给大家在模型的开发应用上带来了借鉴和方便,更重要的是大模型的发展条件已经完全成熟。
如果时间提前5-10年,全世界范围内能够做大模型的公司和团体,一只手完全可以数的过来,不说模型本身的开发难度,首先算力资源就是限制大模型发展的首要因素,想一想5年轻的算力能力还处于一个什么样的状态就清楚了,现在训练大模型的算力设备都是近3年才发布的,其次还有数据资源的问题,近5年全球的数据增长量,几乎每年翻一倍。因此,大模型的发展并不是一蹴而就的,它是在大算力、大数据发展的加持之下才出现的,大模型时代的发展离不开大算力、大数据的支持。
Ø大算力
大算力是指大型的计算能力,它可以用来处理海量的数据和信息,实现多种复杂的计算任务,如人工智能、科学模拟、数字孪生等。大算力是数字经济时代的新生产力,对推动科技进步、行业数字化转型以及经济社会发展发挥重要作用。
大算力的常用计量单位是每秒执行的浮点运算次数,即FLOPS。比如,阿里云在河北张北智算中心提供了一个算力有12 EFLOPS,即每秒执行1200亿亿次浮点运算,相当于462万台最新款M1的苹果电脑产生的算力。
按照《中国算力白皮书(2022年)》的定义,算力主要分为四部分:通用算力、智能算力、超算算力、边缘算力。通用算力以CPU芯片输出的计算能力为主;智能算力以GPU、FPGA、AI芯片等输出的人工智能计算能力为主;超算算力以超级计算机输出的计算能力为主;边缘算力主要是以就近为用户提供实时计算能力为主,是前三种的组合。

根据中国信息通信研究院的测算,2021年我国基础设施算力规模达到140 EFLOPS,位居全球第二;计算设备算力总规模达到202 EFLOPS,全球占比33%,增速达到50%,其中智能算力成为增长驱动力,增速达到85%。
我国已形成体系较完整、规模体量庞大、创新活跃的计算产业,涌现一批先进计算技术创新成果,计算芯片、计算系统、计算软件等环节持续取得突破,新兴计算平台和系统加速创新,前沿计算技术多点突破。
我国消费和行业应用算力需求增长迅猛,互联网依然是最大的算力需求行业,制造业、金融、医疗等领域
也有较大提升潜力。我国以计算机为代表的算力产业规模达到2.6万亿元,直接和间接分别带动经济总产出2.2万亿和8.2万亿元。
Ø大数据
大数据是指规模巨大、类型多样、速度快、价值密度低的数据集合,它超出了传统数据处理软件的能力范围,需要新的技术和方法来进行分析和利用。大数据具有以下特征:
大量(Volume):大数据的数据量非常庞大,通常以TB(太字节)、PB(拍字节)或EB(艾字节)为单位来衡量。例如,据统计,2020年全球互联网用户产生的数据量达到59ZB(泽字节),相当于每天产生160亿GB的数据。
高速(Velocity):大数据的数据流动速度非常快,需要实时或近实时地进行收集、处理和分析。例如,每天有数十亿条微博、微信等社交媒体信息在网络上流动,每秒钟有数百万次的搜索请求在搜索引擎上发生,每分钟有数千小时的视频在视频平台上上传。

多样(Variety):大数据的数据类型非常多样,包括结构化的数据(如数字、文本等)、半结构化的数据(如XML、JSON等)和非结构化的数据(如图像、音频、视频等)。这些数据来自于不同的来源,如传感器、日志、社交媒体、网页、文档等。
价值(Value):大数据的价值密度相对较低,也就是说,其中有用的信息只占一小部分,需要通过有效的分析方法才能挖掘出来。例如,一张照片中可能只有人脸或物体的部分信息是有价值的,而其他的背景或噪声则是无用的。
真实(Veracity):大数据的真实性和可靠性也是一个重要的问题,因为大数据中可能存在不准确、不完整、或重复数据,这会影响数据质量和分析结果。因此,需要对大数据进行清洗、整合等操作来提高真实性。
Ø大模型
大模型是指具有大量参数和计算资源的机器学习模型,通常在训练过程中需要大量的数据和计算能力,并且具有数百万到数十亿个参数。大模型的设计目的是为了提高模型的表示能力和性能,在处理复杂任务时能够更好地捕捉数据中的模式和规律。
大模型的发展源于自然语言处理领域,以谷歌的BERT、OpenAI的GPT和百度文心大模型为代表,参数规模逐步提升至千亿、万亿,同时用于训练的数据量级也显著提升,带来了模型能力的提高。
大模型通常采用预训练+微调的方式,即先在海量无标注的数据上进行自监督学习,然后根据具体的下游任务进行少量数据的微调,以实现更优的识别、理解、决策、生成等效果。
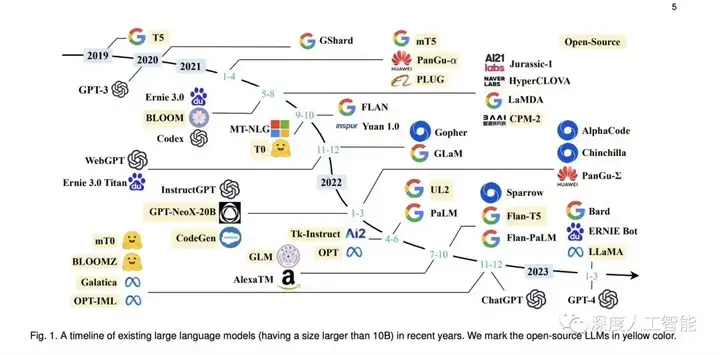
大模型在推进产业智能化升级中已表现出巨大潜力,可以应用于搜索、推荐、智能交互、AIGC、生产流程变革、产业提效等场景。大模型也面临着一些挑战和风险,如算力成本高昂、数据质量和安全问题、模型可解释性和可信度问题等。
大模型的参数数量非常庞大,这使得它们能够更好地捕获数据中的复杂关系和模式。这对于在各种任务上实现出色的性能非常有帮助。
大模型通常有更深的神经网络结构,包括多个层和子网络,这有助于模型对数据进行多层次的特征提取和抽象。
大模型通常会通过在大规模数据上进行预训练来获得广泛的知识,然后可以在特定任务上进行微调,以实现更好的性能。这种预训练-微调策略在自然语言处理领域非常成功。
由于大模型的规模和复杂性,它们需要大量的计算资源进行训练和推断。通常需要使用高性能的计算单元,如GPU(图形处理单元)或TPU(张量处理单元)来支持大模型的运算。
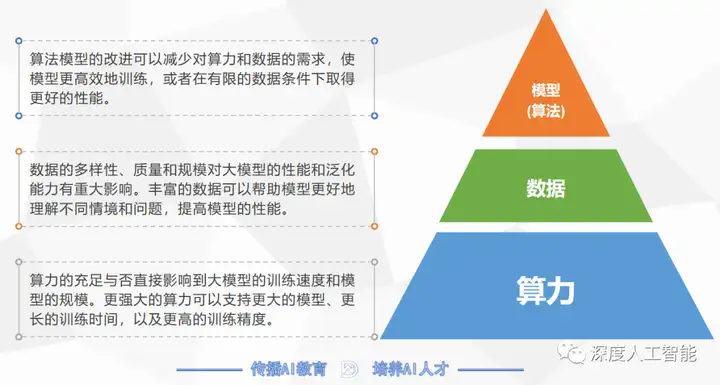
算力、数据、算法模型三者共同构建了大模型应用的发展生态,三者的关系也是相互依存、缺一不可的。算力的充足与否直接影响到大模型的训练速度和模型的规模,更强大的算力可以支持更大的模型、更长的训练时间,以及更高的训练精度;数据的多样性、质量和规模对大模型的性能和泛化能力有重大影响,丰富的数据可以帮助模型更好地理解不同情境和问题,提高模型的性能;算法模型的改进可以减少对算力和数据的需求,使模型更高效地训练,或者在有限的数据条件下取得更好的性能。
Ø大模型的主要能力和问题
和众所周知的AlphaGo不同,以ChatGPT为代表的大模型之所以能够被大众所熟知和使用,不仅仅是感叹于它的神奇之处,更多的是来自于对大模型带来的实际应用价值,而这种实际应用价值对于每一个普通人而言,都是有非常大的帮助。相比AlphaGo只对围棋领域的影响,而以ChatGPT、DALL-E为主的大模型则是对整个人类的表达和创作方式进行了革命。
大模型的应用如雨后春松般的出现,并能够被大众所接受,主要来自于它的各种能力。首先是他的迁移学习能力,大模型具有强大的知识和记忆能力,可以从海量的语料中学习到丰富的语义和知识表示,并在下游任务中进行迁移学习。如果从头训练一个大模型,它所花费的时间将是很漫长的,目前的大模型都是利用迁移学习的方式来提高训练效率的。

其次,大模型强大的表达能力使其对各类问题几乎拥有和人类一样的理解,大模型具有惊人的生成和理解能力,可以根据内部表示生成新的信息,如图像、声音、文本等,并能够理解言外之意、隐喻、幽默等复杂的语言现象。
另外大模型还具有人类独有的创造学习,大模型具有潜在的学习推理和规划能力,可以根据目标进行推理和决策,并通过反馈与环境交互,甚至能够塑造环境。它能够根据现有的数据信息推测未来,能够根据描述创作出符合条件的各类作品。
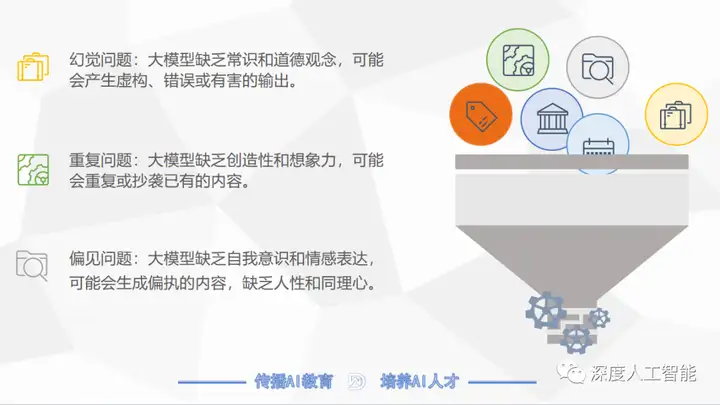
大模型的能力固然强悍,但是同时也要正视大模型目前存在的一系列问题,比如被常常诟病的幻觉问题,大模型往往缺乏常识和道德观念,可能会产生虚构、错误或有害的输出。大模型除了幻觉问题,还存在重复输出内容的问题,有时候大模型会出现缺乏创造性和想象力的内容,会重复输出相似的内容,或抄袭已有的内容。
在国外,大模型的输出内容最被不能接受的就是偏见问题,我们知道国外对人种歧视和性别歧视比较敏感,而大模型缺乏自我意识和情感表达,经常会出现一些歧视性的内容,会生成偏执的内容,让人们认为是缺乏人性和同理心的。
当然,随着大模型技术的发不断发展,无论是幻觉问题、重复输出问题,还是偏见歧视问题,都会慢慢有所改进的,未来我们使用到的AI Agent将会更加智能,更像一个真正的人类。
二、大模型的现状和未来
Ø大模型对企业的影响
目前大模型在企业之间的竞争已经逐渐趋向白热化,到了明年,企业之间的大模型应用竞争会更加激烈,尤其是大企业之间,各自都在争抢市场占有率,这和移动互联网时代的情况有些类似。
有一个共识就是大模型的应用会逐渐渗透到各行各业中,目前已经有很多行业和企业受到了大模型的直接影响,比如金融行业的信息评估预测、医疗行业的影像分析和药物研发、零售行业的销售分析和市场预测、制造业的生产数据分析和调度计划等。

互联网企业的用户敏感度最高,因此大模型对互联网企业的冲击会更大。尤其是大企业,如果没有自己的大模型生态,那么意味着将来可能会受制于人,或者发展受阻;而小企业没有太大的实力和大企业去竞争,更多的是依附各大企业的生态体系下,发展自己的业务。大模型的发展对各大互联网厂商来说,几乎已经是必选项,要么积极拥抱,要么等待出局。
Ø大模型的扶持政策
和企业间的竞争相比,国家和各地政府对大模型的发展更是倾注了大量补助和优惠政策。2023年4月28日,中央政治局会议强调“要重视通用人工智能发展,营造创新生态,重视防范风险”。当下,全国已有北京、深圳、成都、杭州、无锡、上海、重庆多城面向AI大模型时代推出了新政策或政策意见稿。
7月8日,在2023世界人工智能大会闭幕式上,《上海市推动人工智能大模型创新发展的若干措施》(下称《若干措施》)公布,并发布了“模”都倡议,成立上海人工智能开源生态产业集群,打造AI“模都”。上海将携手海内外各类英才全力推进卓越引领的“模”都上海建设,打造大模型企业人才集聚的创新高地,鼓励在沪开展大模型的研发和产业化,对重点项目及人才团队给予优先的政策支持,打造最具竞争力的创新环境,加大资金的支持力度,对新增的大模型、高水平的算力、智能算力建设和使用,给予分级分类的支持,进一步壮大人工智能产业基金的规模,引导和撬动市场资本。

8月2日,杭州计划为符合要求的通用大模型研发单位提供最高不超过5000万元的补助,且每年评选不超过10个性能先进并在杭成功落地的优秀专用模型,提供最高不超过500万元的补助金额。补助(奖励)资金由市和各区、县(市)按财政体制共同承担。
在8月27日举行的2023长三角算力发展大会上,苏州市发布《苏州市关于推进算力产业发展和应用的行动方案》,明确提出到2025年的智算算力目标,并公布对半导体和集成电路、EDA、大模型、软件和信息服务等算力企业的一系列资金支持和补助,最高奖励或补助高达1000万元。
8月29日,武汉“光谷软件十条”提出支持开源平台建设,最高补贴3000万元,鼓励进行重大开源项目的软件开发,孕育出原创性、爆炸性、轰动性的具有全球影响力的大模型。最新一轮武汉数字经济应用场景“揭榜挂帅”项目中,新设立“人工智能大模型典型应用场景”榜单,鼓励人工智能企业依托大模型技术开发应用。

北京为支持中关村科学城通用人工智能产业发展,鼓励大模型创新研发,制定2023年中关村科学城算力补贴专项申报指南。夯实算力基础支撑。对技术创新性强、应用生态丰富的大模型,给予相关创新主体不超过购买或租用算力合同金额的30%、最高1000万元资金补贴。对于重大项目,原则上可根据研发迭代情况,连续支持两年。对技术创新性强、性能好的通用大模型,分档给予1000万元、500万元、300万元资金补贴(不超过购买或租用算力合同金额30%)。对技术创新性强、应用生态丰富的垂直大模型,分档给予300万元、200万元、100万元资金补贴(不超过购买或租用算力合同金额30%)。
除了以上已经明确公布了奖励标准的城市,其他各大城市也都在陆续发布对大模型的支持政策。可见大模型的发展已经是各大城市政府的主要扶持的方向之一了,未来随着大模型的落地应用和产生的实际价值,政策上的倾斜可能还会更大。
从国家层面来说,大模型的发展既是科技和经济增长的长期规划,也是国际竞争的主要方向之一,大模型的应用不仅可以用于民生方向,同时也可以用于军事领域。而一个国家的发展,离不开科技的发展、经济的发展,以及军事力量的发展。

Ø大模型的发展方向
目前大模型的应用大部分都聚集于通用模型,通用模型的优势是一个模型能够解决多类问题,比如大众熟知的ChatGPT、文心一言等模型,就是一个通用模型,它既能够对话聊天、写文章,也能够解决一般的数学问题,还能够进行代码编程,几乎跟文本相关的各类问题,它都能够去做。
通用模型的弱点也来自于此,由于模型同时能够执行多种任务,那么它的参数就不会降下来,而且在数学、编程等各类专业问题的解答上并不如人意,这是多方面的因素造成的,一方面想要模型能够解决多类问题,那么所准备的训练数据就需要对应各类问题中的各种场景,这本身就不是一件容易的事,更何况就算准备了大量的数据,在进行人类反馈强化学习(RLHF)的时候,也需要各位问题的专家来鉴别模型的输出是否合理。
另一方面,模型要解决的问题类型越多,往往意味着模型的复杂度会提高,它的参数分布就越分散,方差也会变大,因为这些参数需要去拟合各类任务,可能会导致这些参数很难优秀的解答每一个问题,大部分情况就是各类问题都能拿到中位分数,很难拿到高分,想要解决这个问题,就需要更大参数的模型。
一般来说,在解决多模态任务的时候,模型的参数量越大,模型的复杂度就越高,这意味着模型有更强的拟合能力,可以捕捉到更复杂的特征和关系。因此,在数据量充足的情况下,大参数模型通常可以获得更好的性能。但是如果数据量不足,过大的模型参数量可能会导致过拟合。随着模型参数量的增加,训练和推理所需的计算资源也会相应增加。从而导致训练时间过长,或者对硬件设备有较高的要求。
理论上来说,可以通过增加模型的参数来提高模型的能力,但是在实际的应用上,这并不是唯一的选择,相反在很多时候,需要降低模型的参数让模型在各种设备上能够运行,不但能够提高模型的部署效率,还能节约很多算力资源。
大模型小型化是未来的发展趋势,比如微软发布的Phi1.5-1.3B模型,以及国内上海人工智能实验室发布的InternLM-20B模型,都在保证模型能力的前提下做参数瘦身,尽可能地降低模型的参数来适应各类实际应用场景,相信在未来,随着大模型的技术发展,大模型相对而言可能并不“大”,这和第一台计算机从房子大小变成现在的掌上工具一样,大模型也需要这样一个发展的过程,从而让大模型更加平民化。
就目前大模型的发展而言,通用大模型小型化带来的效果远没有专业大模型小型化带来的效果好,一般来说,同样参数的专用模型在各类指定任务的效果上肯定优于通用模型,未来专用模型在各领域的实际应用价值也要高于通用模型,这一点可以参考MathGPT解决数学问题的能力和CodeGPT解决编程问题的能力,这些专用大模型在各自的领域里,其能力是远超于通用大模型的,而且专用大模型的商业价值也要远高于通用大模型。

未来大模型的发展将从通用模型发展到专用模型,进一步还会发展到世界模型,构造自主 AI则需要预测世界模型,而世界模型必须能够执行多模态预测。可见大模型的发展既是企业持续,也是国运之争,更是全人类共同走向AGI之门的钥匙。












