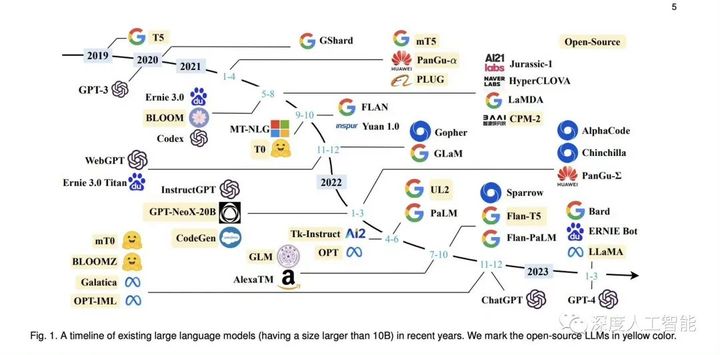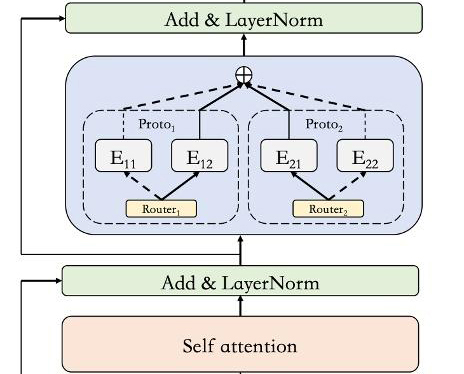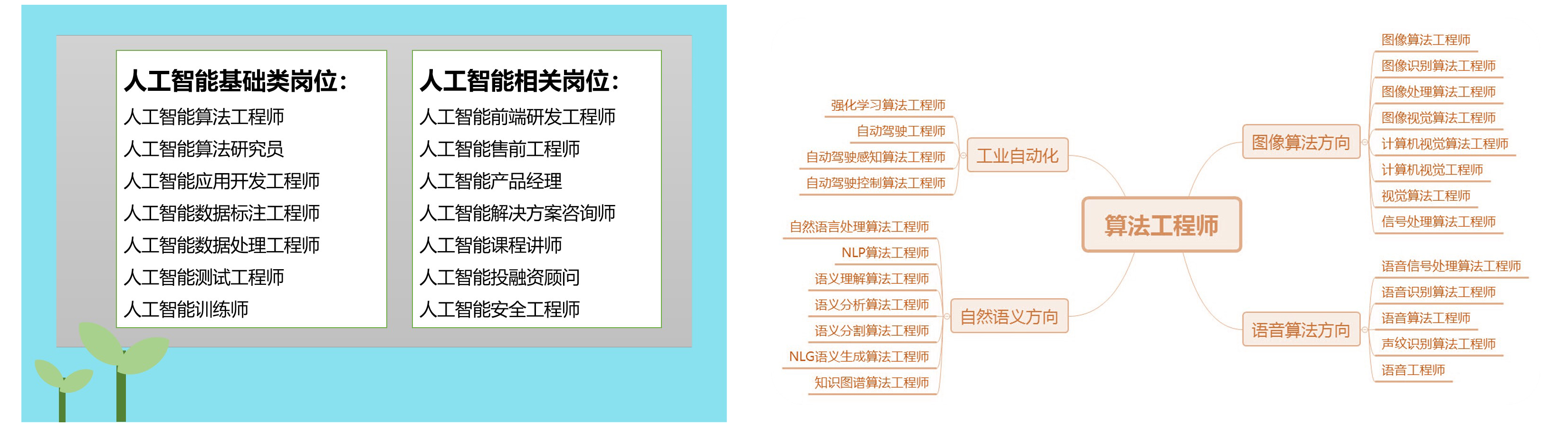
随着人工智能的发展,企业对人工智能的从业人员也有了更标准化的要求,人工智能方向的相关证书也受到了用人单位的重视,工信部教考中心的《人工智能算法工程师》是非常受欢迎的证书,对于普通人考取这个证书,最好的方法就是参加线上培训,学习完课程后再参加考试,能够极大的提高考试的通过率。
根据中国教育部门测算,我国人工智能人才目前缺口超过500万,国内人工智能行业的综合人才供求比例为1:10,根据工信部发布的《人工智能产业人才发展报告》显示,计算机语音、视觉方面的人才供需比例更是低到0.08、0.09,供需比例严重失衡。不断加强人才培养,补齐人才短板,是我国的当务之急。本课程适合大学毕业准备就业的同学、其他行业转行人员、互联网软件行业技能提升人员等。
人工智能专业的考研是在校大学生进入人工智能行业的官方渠道之一,也是考研的热门专业之一。人工智能专业的研究生社会认可度高,从业薪资待遇好,毕业后还能获取人工智能专业的硕士学位证书。本课程适合想要通过读研进入人工智能行业的大学在读生,以及其他专业想要转到人工智能专业的在读生。
随着人工智能的发展,企业对人工智能的从业人员也有了更标准化的要求,人工智能方向的相关证书也受到了用人单位的重视,工信部教考中心的《人工智能算法工程师》是非常受欢迎的证书,对于普通人考取这个证书,最好的方法就是参加线上培训,学习完课程后再参加考试,能够极大的提高考试的通过率。
根据中国教育部门测算,我国人工智能人才目前缺口超过500万,国内人工智能行业的综合人才供求比例为1:10,根据工信部发布的《人工智能产业人才发展报告》显示,计算机语音、视觉方面的人才供需比例更是低到0.08、0.09,供需比例严重失衡。不断加强人才培养,补齐人才短板,是我国的当务之急。本课程适合大学毕业准备就业的同学、其他行业转行人员、互联网软件行业技能提升人员等。
适合脱产学习者,时间相对自由的人群。
专业定制课程,学习自由度最高,可实现一对一教学辅导。
无论就业,还是考研,都可以选择。
适合上班族,晚上时间相对充裕的人群。
一边上班、一边学习,利用八小时外的时间谋取发展。
下班的时间学习充电,实现职业生涯的逆袭。
适合上班族,周末时间相对充裕的人群。
别人在周末刷剧旅游,你在周末充电加油。
半年之后,薪资待遇远超当初的自己和现在的同事。
适合脱产学习者,时间相对自由的人群。
专业定制课程,学习自由度最高,可实现一对一教学辅导。
无论就业,还是考研,都可以选择。
适合上班族,晚上时间相对充裕的人群。
一边上班、一边学习,利用八小时外的时间谋取发展。
下班的时间学习充电,实现职业生涯的逆袭。